The average gap between what treated units experienced and what they would have experienced without the policy.
\(E[Y^0_k\mid\text{Post}]\) — the treated group’s untreated outcome — is a counterfactual we never observe. DiD reconstructs it from the control group.
Difference twice: kill the level gap, then kill the common trend
The first difference removes time-invariant differences between groups; the second removes the trend common to both.
Algebra splits this into \(\underbrace{\text{ATT}}\) plus a \(\underbrace{\text{non-parallel-trends bias}}\). The bias vanishes exactly when parallel trends holds.
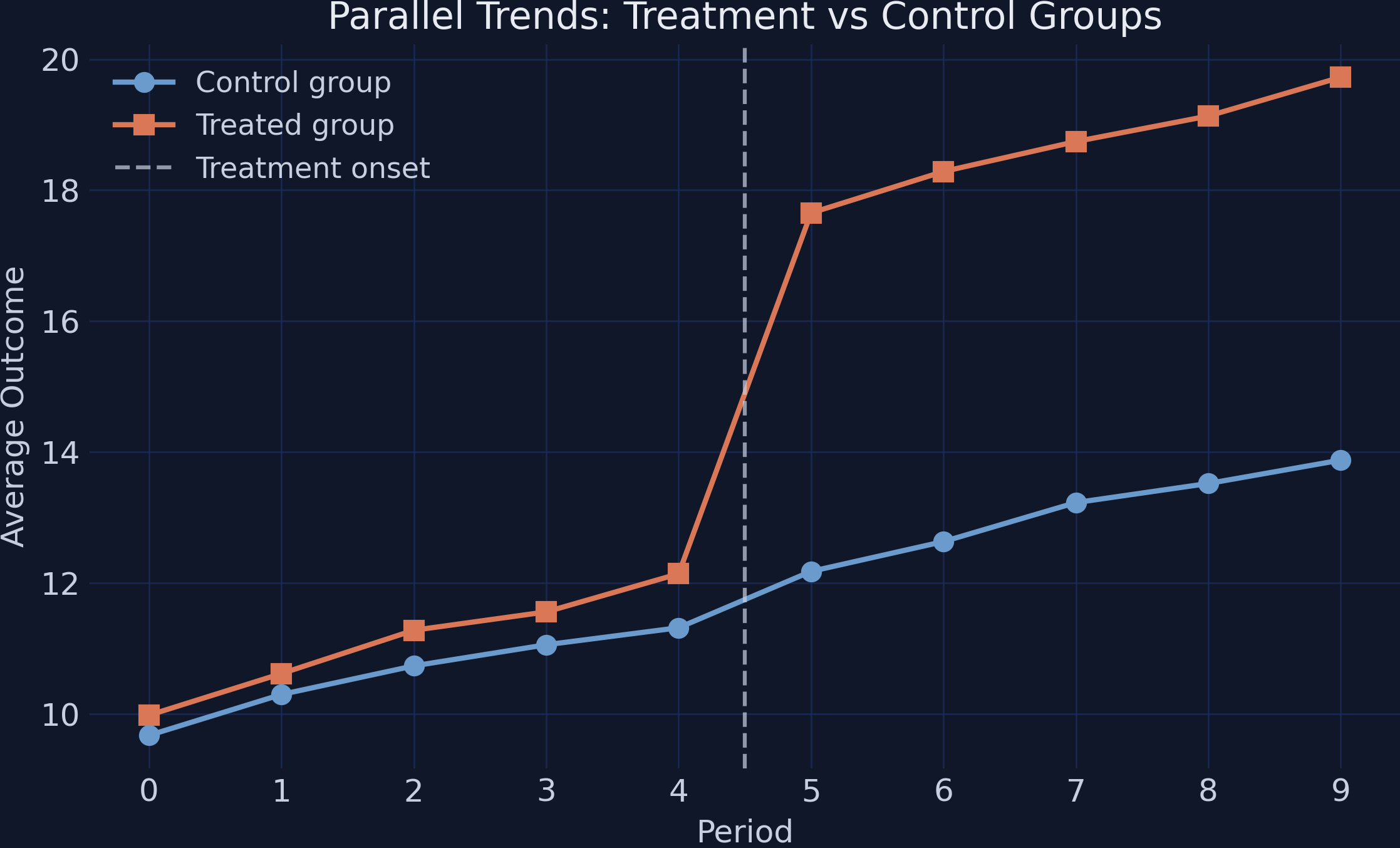
Parallel trends is about slopes, not levels — and it is fundamentally untestable
Two cities can sit at different score levels; DiD only needs them to have been rising at the same speed absent treatment.
We can check pre-treatment trends, but never the post-treatment counterfactual — which is why Act III brings sensitivity analysis.
The lab: a 100-unit, 10-period panel built with a known true effect of 5.0
1,000 observations — 100 units × 10 periods (0–9)
50 treated, 50 control; treatment switches on at period 5
True effect = 5.0 baked in, so every estimate has a ground truth to hit
A built-in true_effect column gives every estimate a known target to hit.
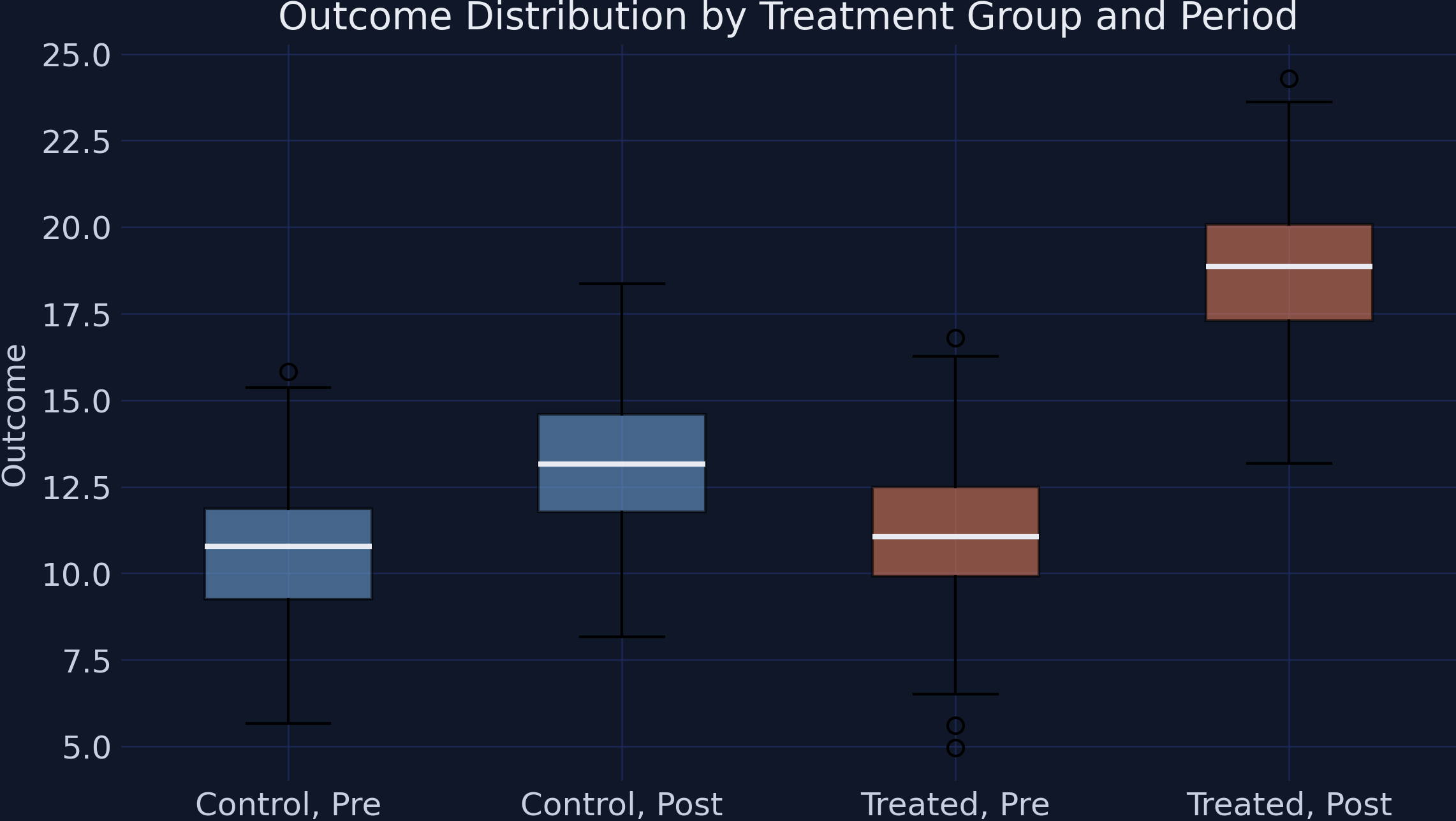
Before treatment the two groups overlap; after, the treated box jumps far higher
Outcome distributions by group × period. Control (steel) and treated (orange) overlap pre-treatment near 10.6–11.1; the treated box jumps to ~18.9 post-treatment.
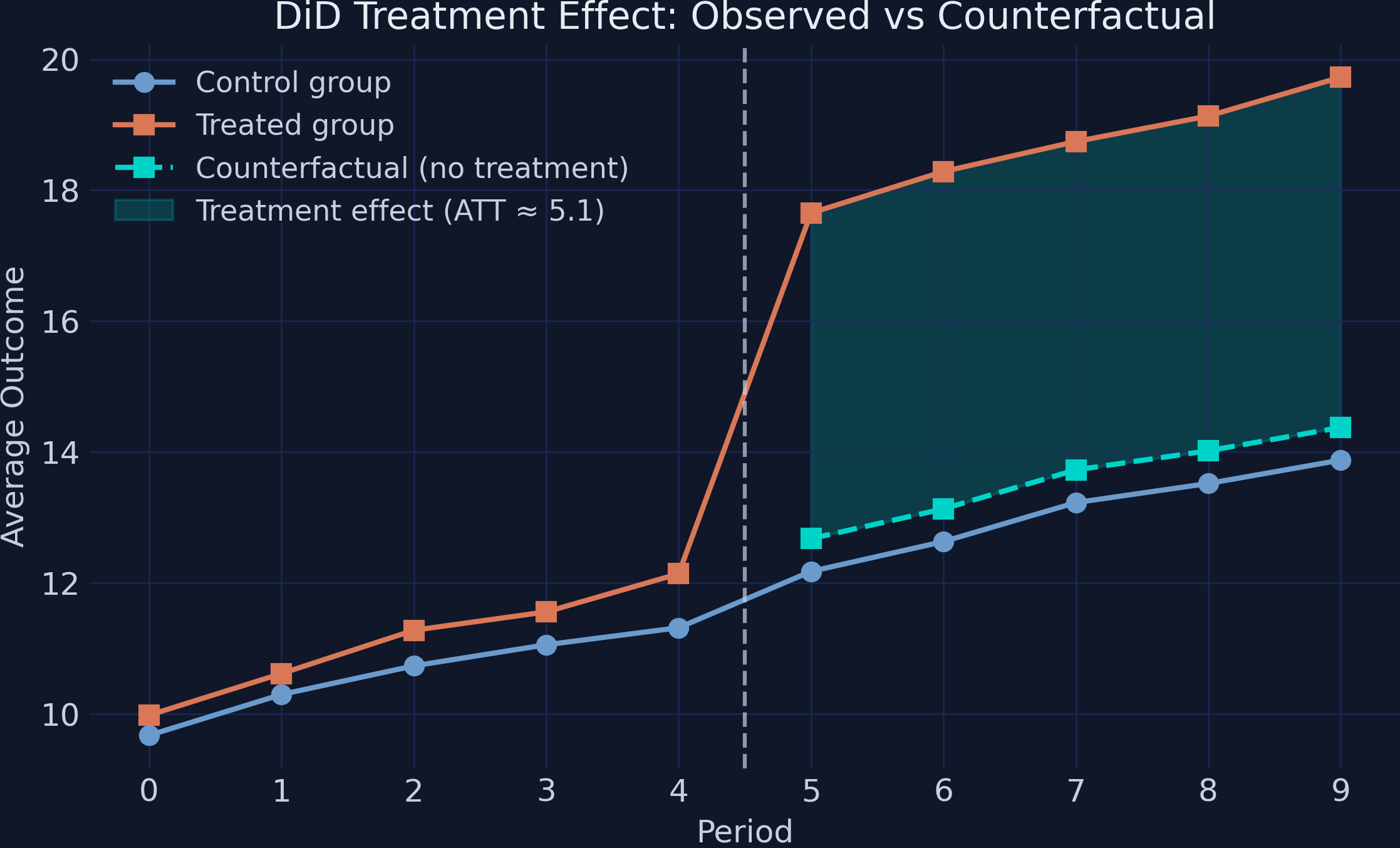
The shaded gap is the causal effect: treated outcomes minus their projected counterfactual
The teal dashed line is the control group’s path shifted to the treated group’s pre-level — the no-treatment counterfactual. The shaded gap is the ~5.1 ATT.
Six lines fit the classic 2×2 estimator with the diff-diff package
from diff_diff import DifferenceInDifferences, generate_did_datadata = generate_did_data(n_units=100, n_periods=10, treatment_effect=5.0, treatment_period=5, seed=42)did = DifferenceInDifferences()res = did.fit(data, outcome="outcome", treatment="treated", time="post")res.print_summary() # ATT = 5.1216, 95% CI [4.6399, 5.6034]
The classic estimator recovers 5.12 — within 2.4% of the true 5.0
5.12
Classic 2×2 \(\widehat{\text{ATT}}\) (SE 0.25, \(t = 20.9\)) · 95% CI [4.64, 5.60] covers the true 5.0
A formal pre-trends test fails to reject parallel trends: slope gap 0.12, p = 0.29
Group
Pre-trend slope
SE
Treated
0.5262
0.0839
Control
0.4047
0.0798
Difference
0.1216
0.1158
\(t = 1.05\), \(p = 0.29\) — fail to reject equal slopes. But failing to reject is not confirming: the test has low power with only 5 pre-periods.
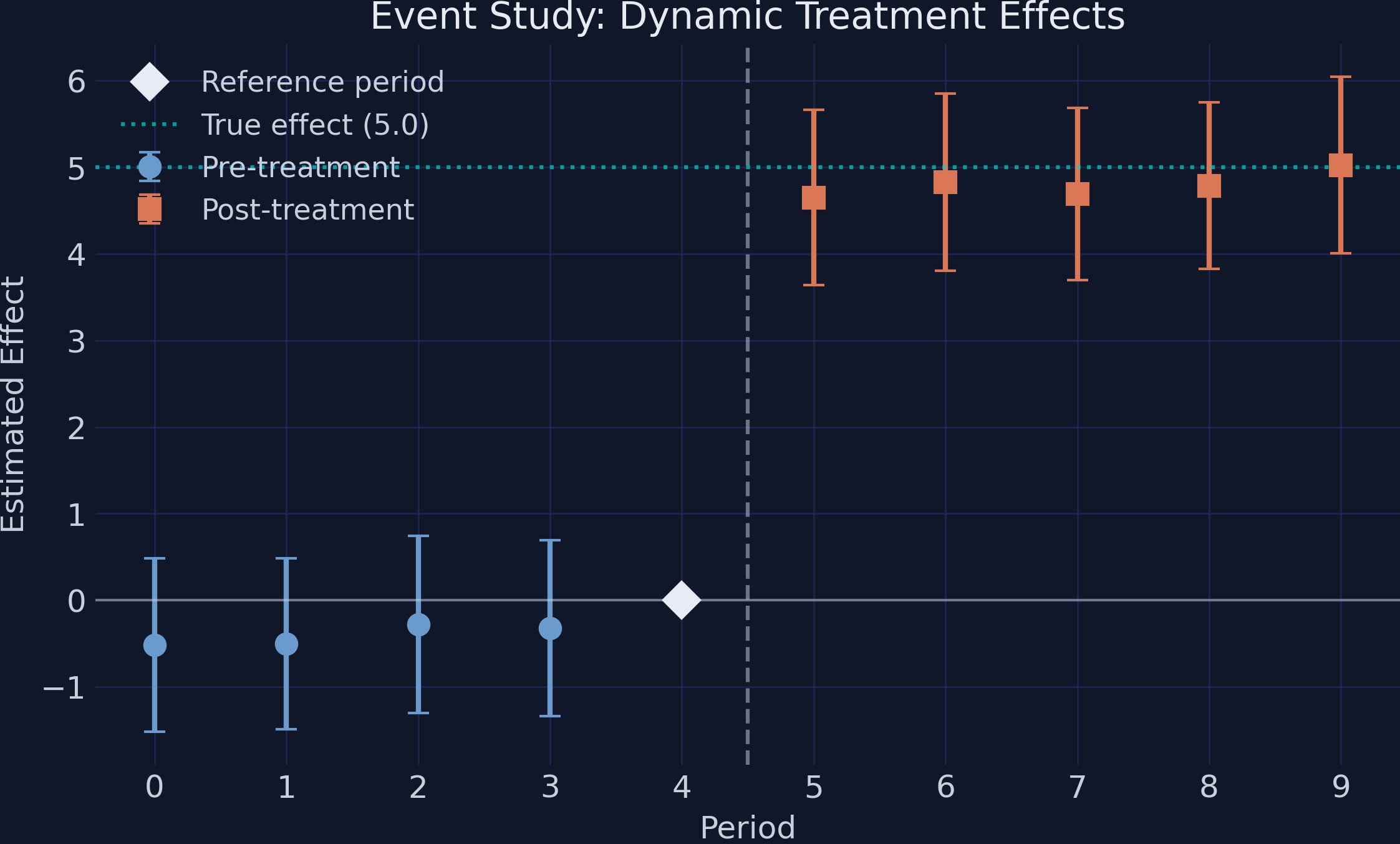
The event study splits the single ATT into one effect per period relative to treatment
The leads\(\beta_k^{lead}\) are placebo tests (should be ~0); the lags\(\beta_k^{lag}\) trace how the effect evolves. The period before treatment is the omitted reference.
Leads sit on zero, lags snap to ~5.0 — the visual signature of a clean DiD
Pre-treatment coefficients (steel) hover at zero with CIs crossing it; post-treatment coefficients (orange) jump to ~5.0, matching the teal true-effect line.
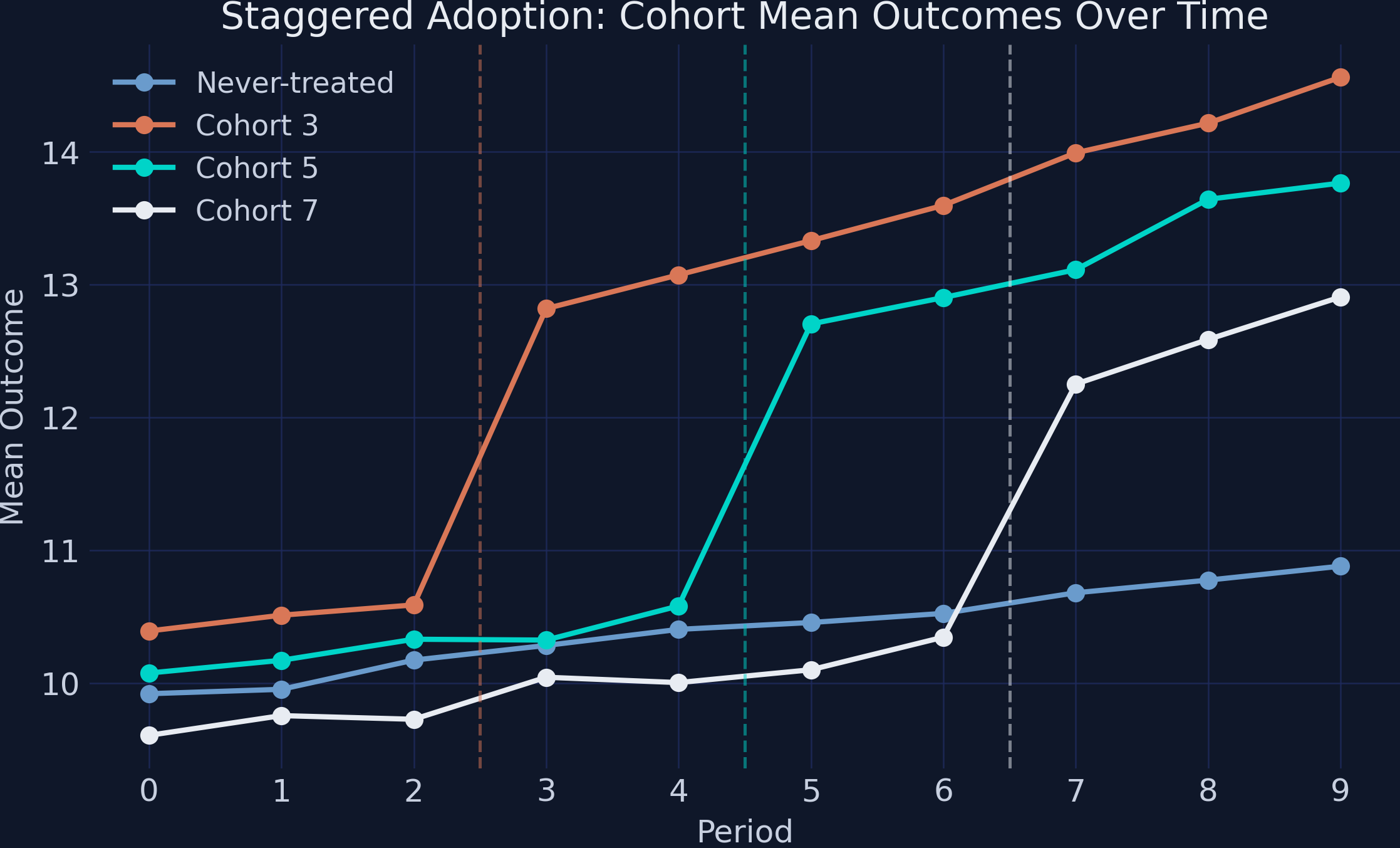
Real policies roll out city by city — and that staggered timing breaks naive TWFE
3,000 observations — 300 units × 10 periods
Three cohorts adopt at periods 3, 5, 7 (60, 75, 75 units)
90 never-treated units — a clean control group
Effects grow over time by construction (2.0 → 3.2 for the earliest cohort)
TWFE fits one pooled \(\delta\) — a weighted average of many 2×2 comparisons, some of them poisoned.
Cohorts move in parallel, then jump at their own onset — TWFE then mis-uses early adopters as controls
Four cohorts track together pre-treatment, then cohort 3 (orange), 5 (teal), 7 (near black) each jump at its onset; never-treated (steel) drifts gently up.
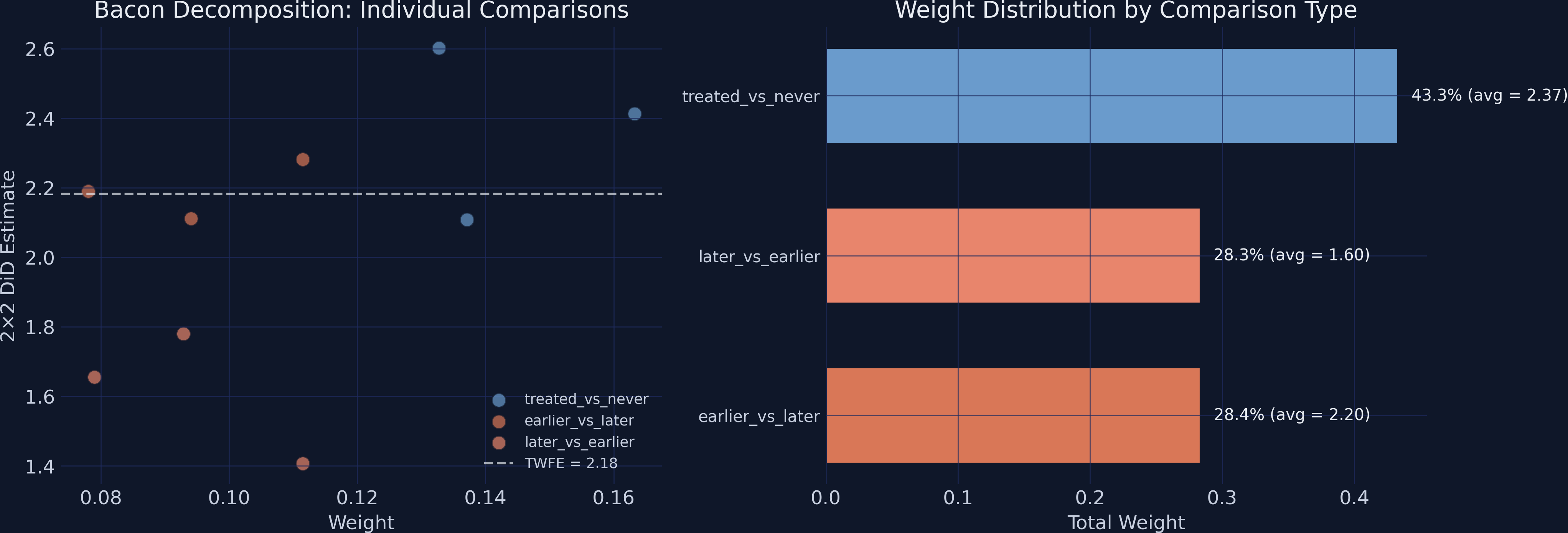
The Goodman–Bacon decomposition shows 28.3% of TWFE’s weight is on forbidden comparisons
Left: each 2×2 comparison as a point, forbidden ones (dark orange) cluster low. Right: weight by type — nearly a third on forbidden comparisons.
Comparison type
Weight
Avg effect
Treated vs never-treated (clean)
0.433
2.37
Earlier vs later treated
0.284
2.20
Later vs earlier (forbidden)
0.283
1.60
Forbidden comparisons drag TWFE down to a biased 2.18
2.18
Naive TWFE \(\hat{\delta}\) · downward-biased by 28.3% weight on forbidden comparisons (avg effect 1.60)
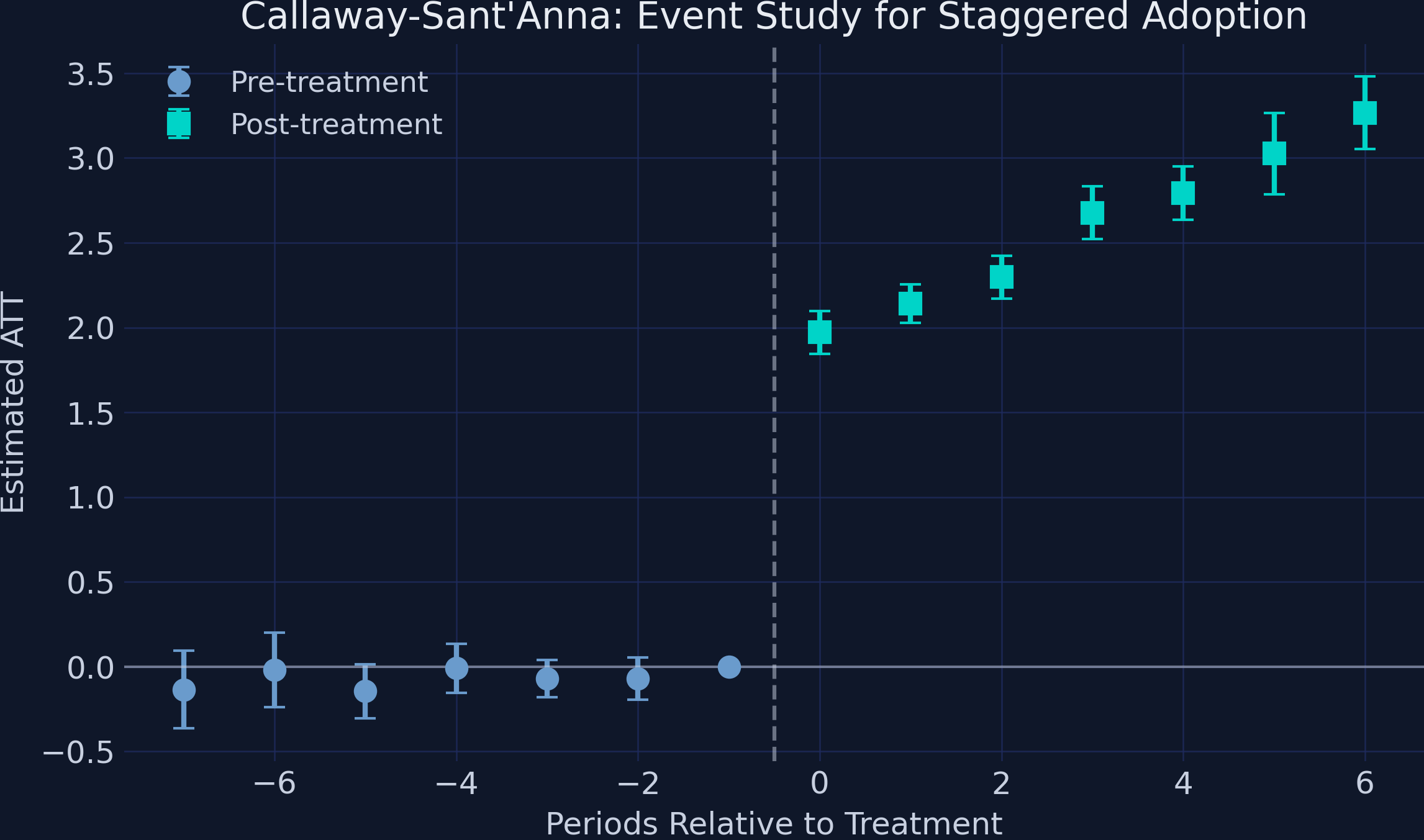
Callaway–Sant’Anna rebuilds the estimate from clean group-time ATTs only
Each building block is a 2×2 that compares cohort \(g\) against the never-treated group only — every forbidden comparison eliminated by construction.
A doubly robust version reweights controls (propensity) and models their outcome change (regression): valid if either is right.
Theory vs naive: same data, but CS uses only valid comparisons
Naive TWFE
one pooled coefficient
28.3% weight on forbidden comparisons
\(\hat{\delta} = 2.18\) (biased low)
hides the dynamics
Callaway–Sant’Anna
clean group-time ATTs
never-treated controls only
overall \(\widehat{\text{ATT}} = 2.41\)
recovers the growth path
CS recovers a clean 2.41, and the effect grows from 1.97 to 3.27 over six periods
CS event study: pre-treatment effects pinned near zero (period −1 = 0 by construction); post-treatment effects rise steadily from ~2.0 to ~3.3.
Does machine-selecting comparisons make this causal? No — parallel trends still carries the weight
Objection. Switching from TWFE to Callaway–Sant’Anna can’t manufacture identification.
Response. Correct. CS only removes contaminated comparisons; the ATT is still identified only under parallel trends and no anticipation. It buys credibility on the timing problem, not on the untestable counterfactual — so we stress-test that next.
The Resolution
Act III
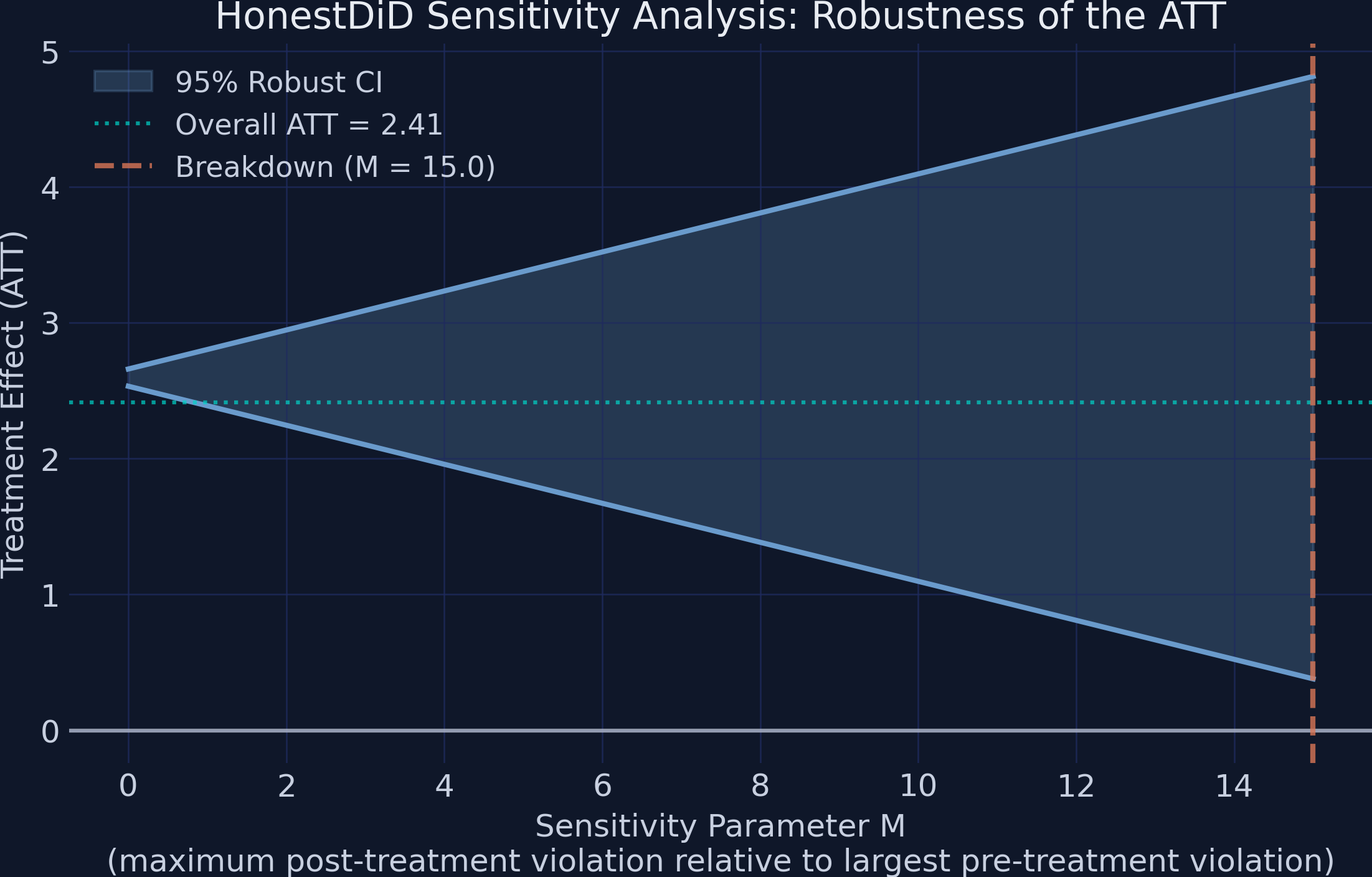
HonestDiD asks: how big a parallel-trends violation before the answer flips?
\[|\delta_t| \leq M \cdot \max_{t' < g}|\delta_{t'}|, \quad \text{for all } t \geq g\]
\(M\) is a stress dial: \(M=0\) assumes perfect parallel trends; \(M=5\) allows post-treatment violations five times the worst pre-treatment one. The breakdown value is where the CI first touches zero.
The CI stays above zero even when violations are 15× the worst pre-trend
Robust 95% CI (steel band) widening with M; ATT (teal) flat at 2.41; the lower bound is still positive (0.38) at the M = 15 grid edge (orange line).
At \(M=0\): CI [2.53, 2.66]. At \(M=15\): CI [0.38, 4.81] — still excludes zero.
The conclusion survives violations 15× worse than anything seen pre-treatment
M = 15
HonestDiD breakdown value · CI excludes zero even at 15× the largest pre-treatment deviation
Three estimators, one honest verdict: the effect is real, growing, and robust
Setting
Estimator
\(\widehat{\text{ATT}}\)
Single timing
Classic 2×2
5.12
Staggered (naive)
TWFE
2.18
Staggered (clean)
Callaway–Sant’Anna
2.41
Always report the breakdown value alongside the estimate — here \(M = 15\), exceptionally robust.
Let the design — not the default regression — choose your comparisons.