Introduction to Causal Inference: Double Machine Learning
Does a cash bonus shorten unemployment? Debiasing an RCT with ML
−0.0736DML · Random Forest
−0.0712DML · Lasso · same answer
5,099UI claimants · randomized
Nagoya University (GSID)
June 11, 2026
The raw gap is real but small: bonus duration sits ~0.09 log points lower
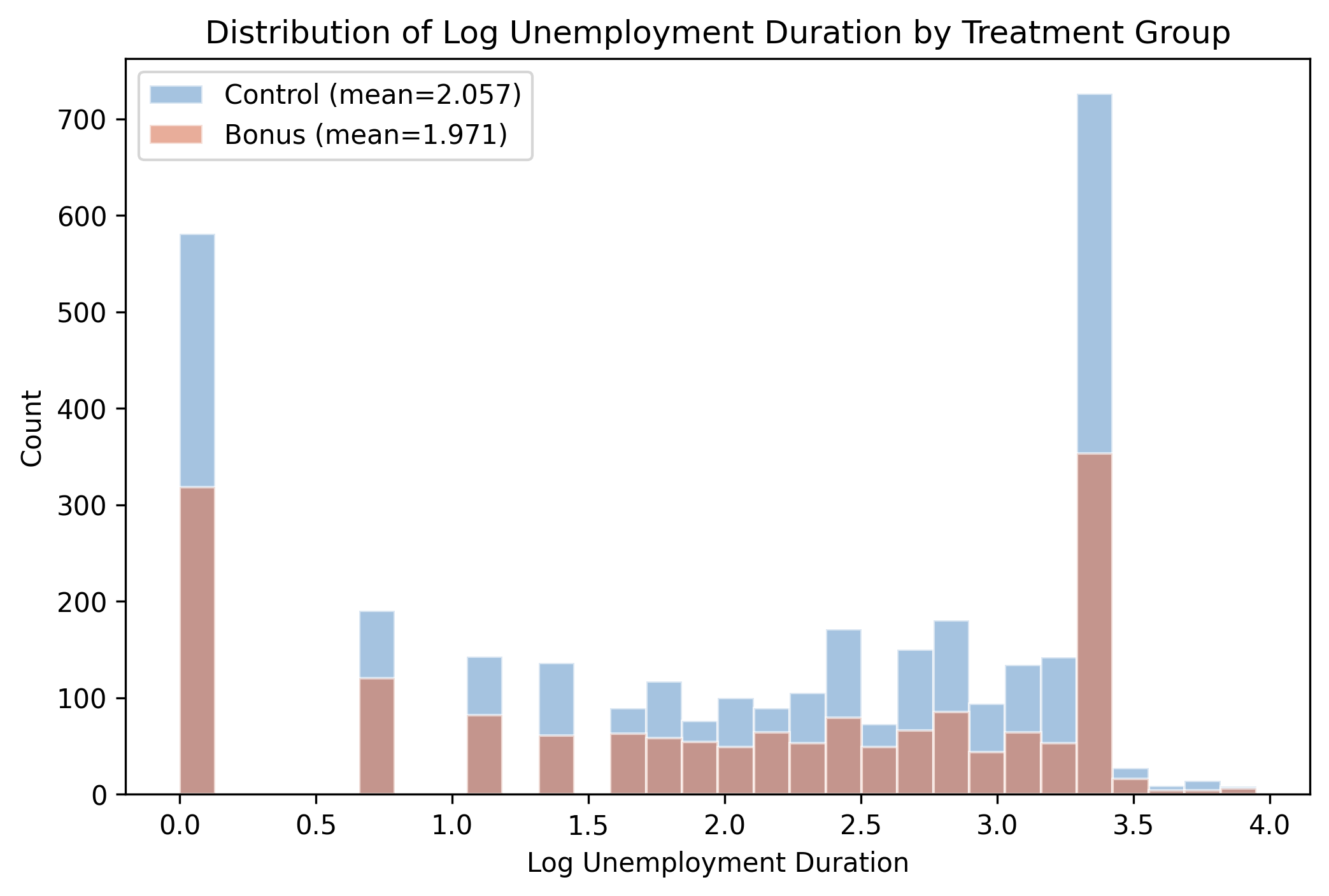
Log unemployment duration by group — both distributions pile up near 3.0–3.5; the bonus group’s mean sits ~0.09 log points lower.
Randomization worked: covariate means line up almost exactly across groups
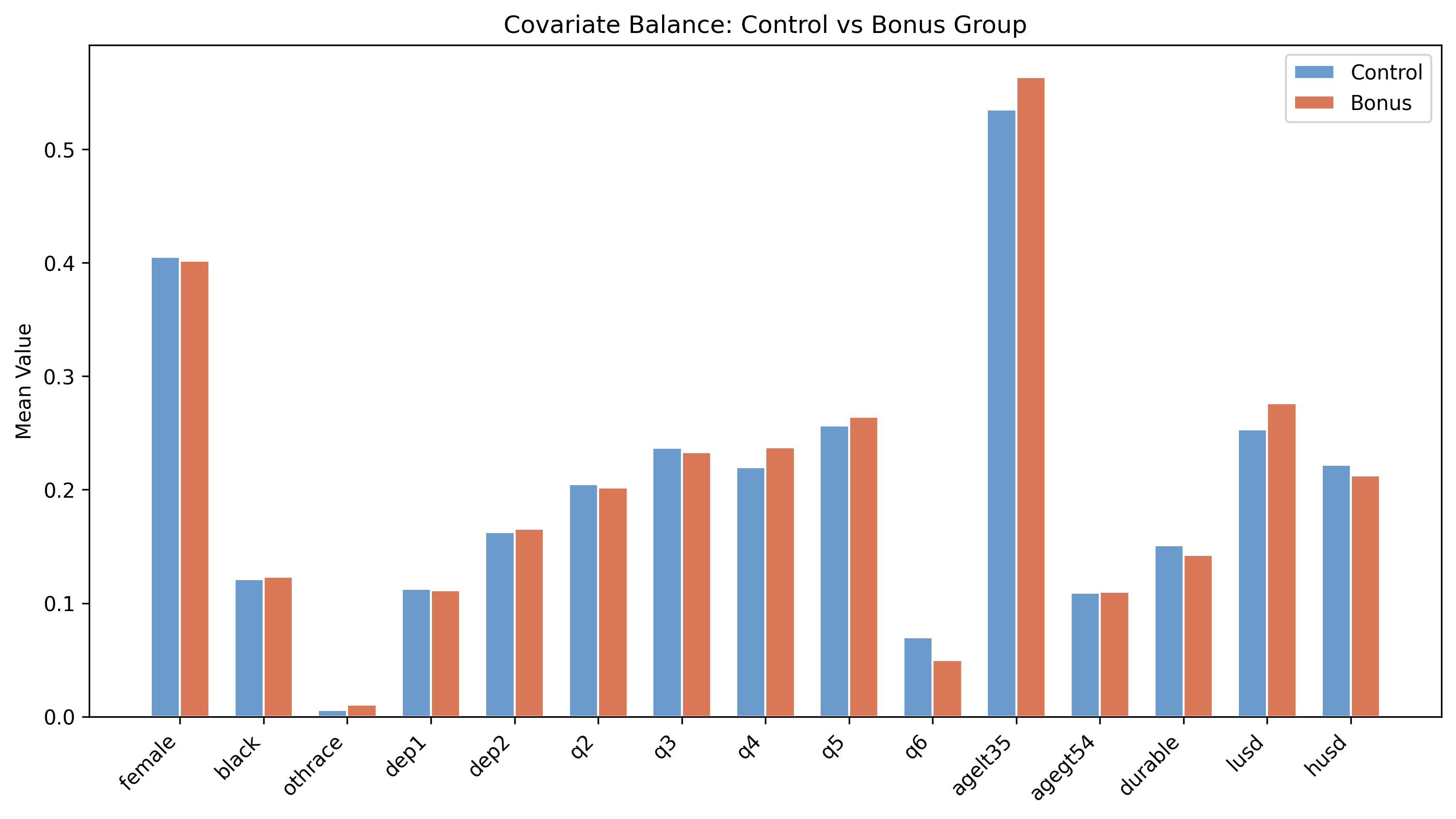
Mean of each of the 15 covariates, control (steel) vs bonus (orange) — the bars are nearly the same height everywhere.
All four roads lead to ~−0.07: the methods agree on sign and size
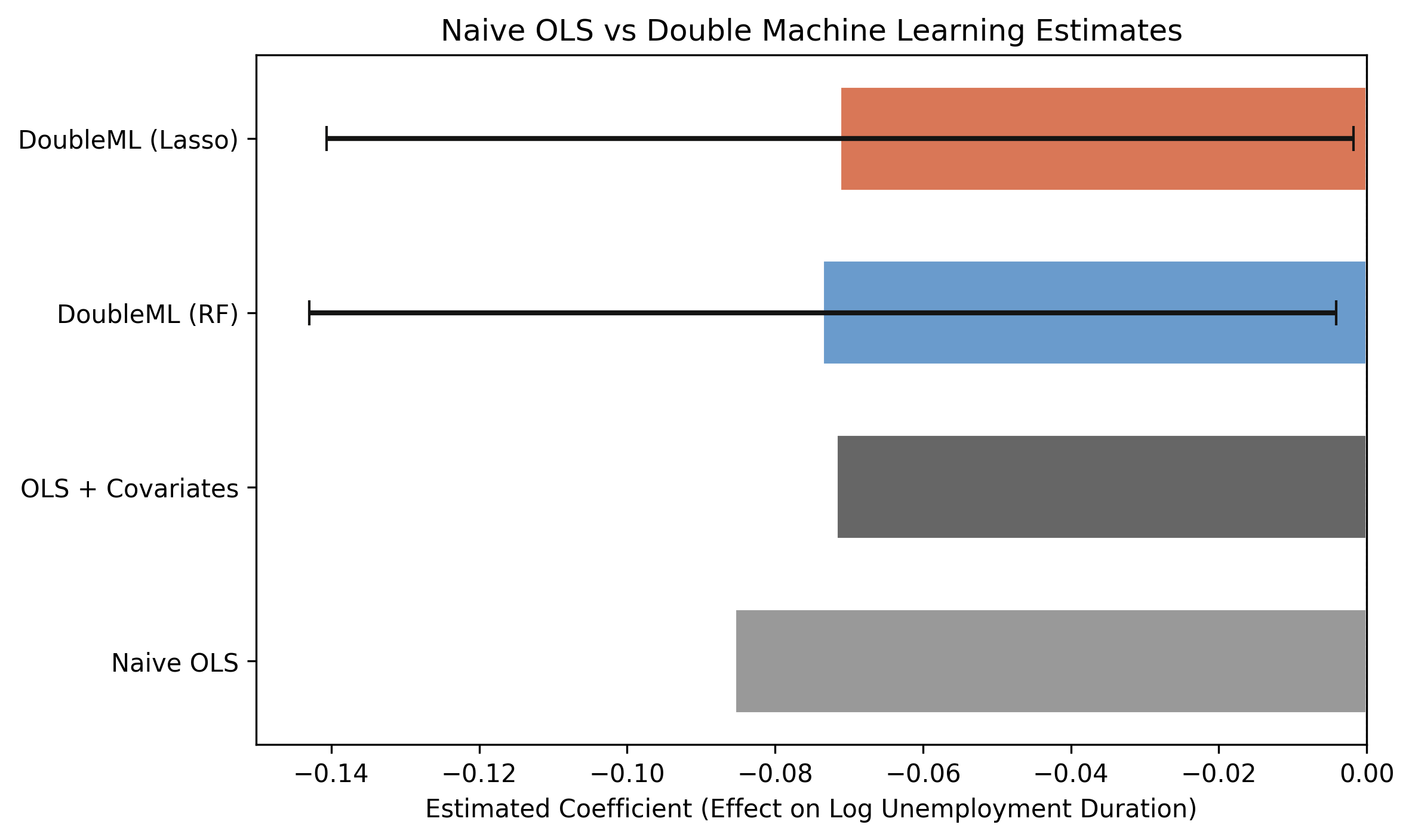
Naive OLS (−0.0855) is largest; covariate OLS and both DML estimates cluster near −0.07. Dashed line = zero; only DML carries valid CIs.
Both DML intervals exclude zero — but only just
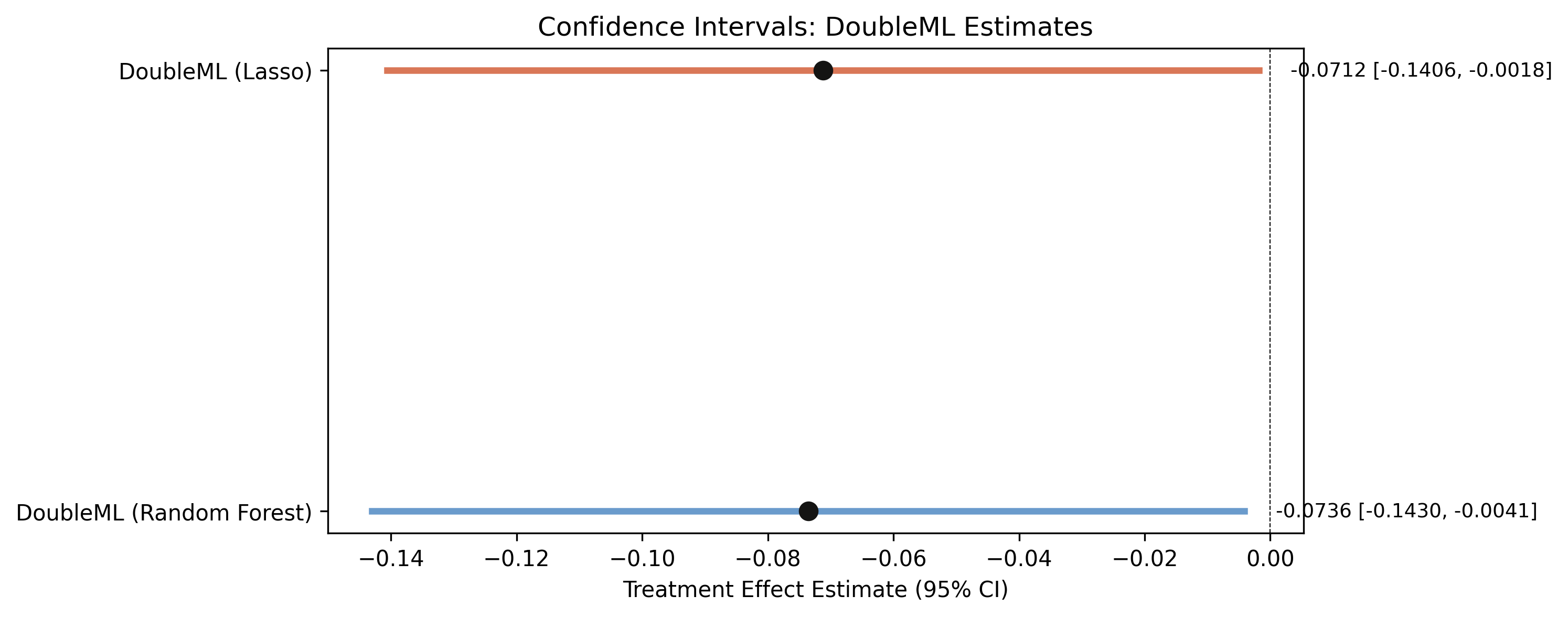
DML-RF [−0.143, −0.004] and DML-Lasso [−0.141, −0.002]; near-identical width, upper bounds hugging zero.