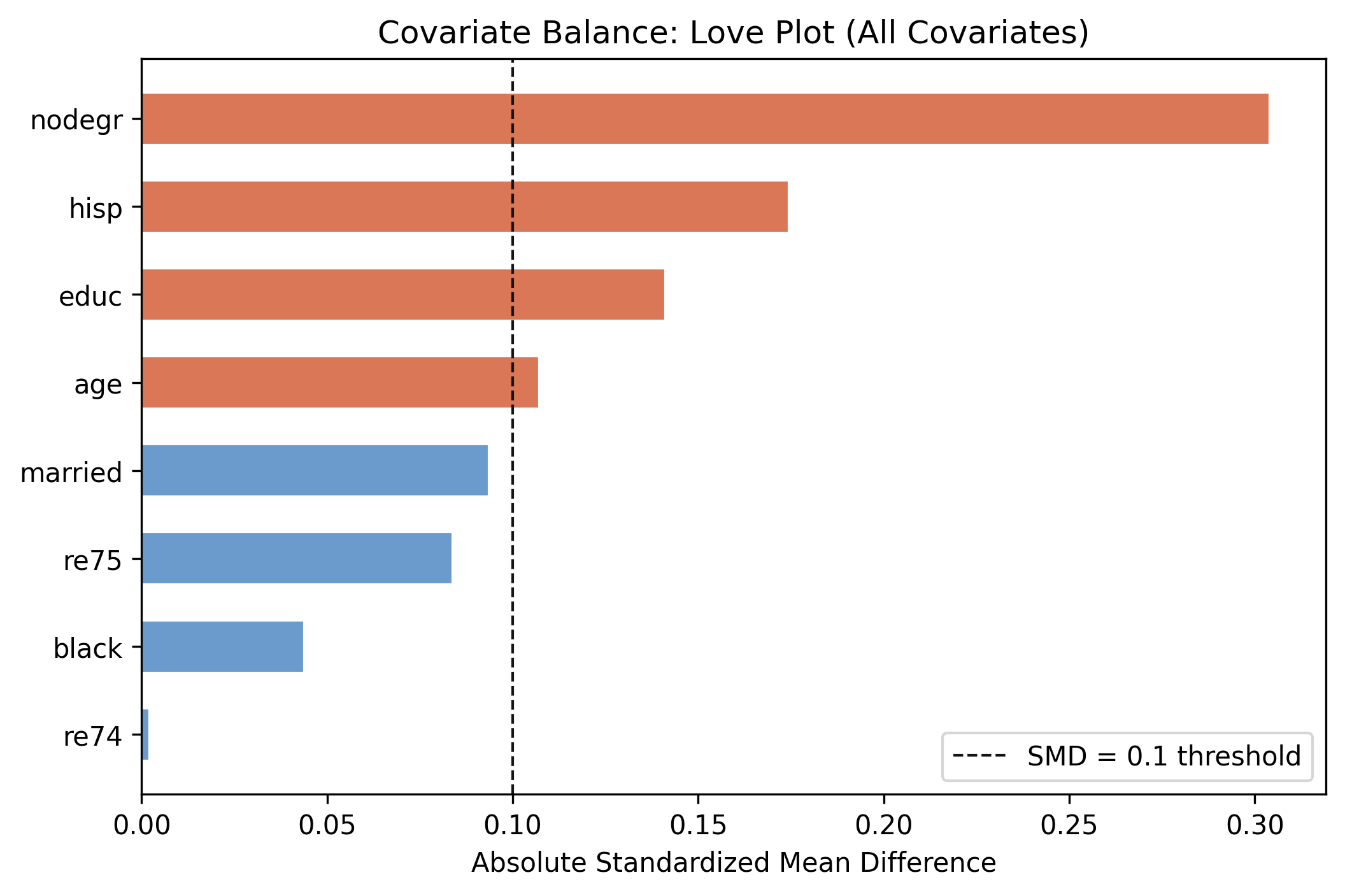
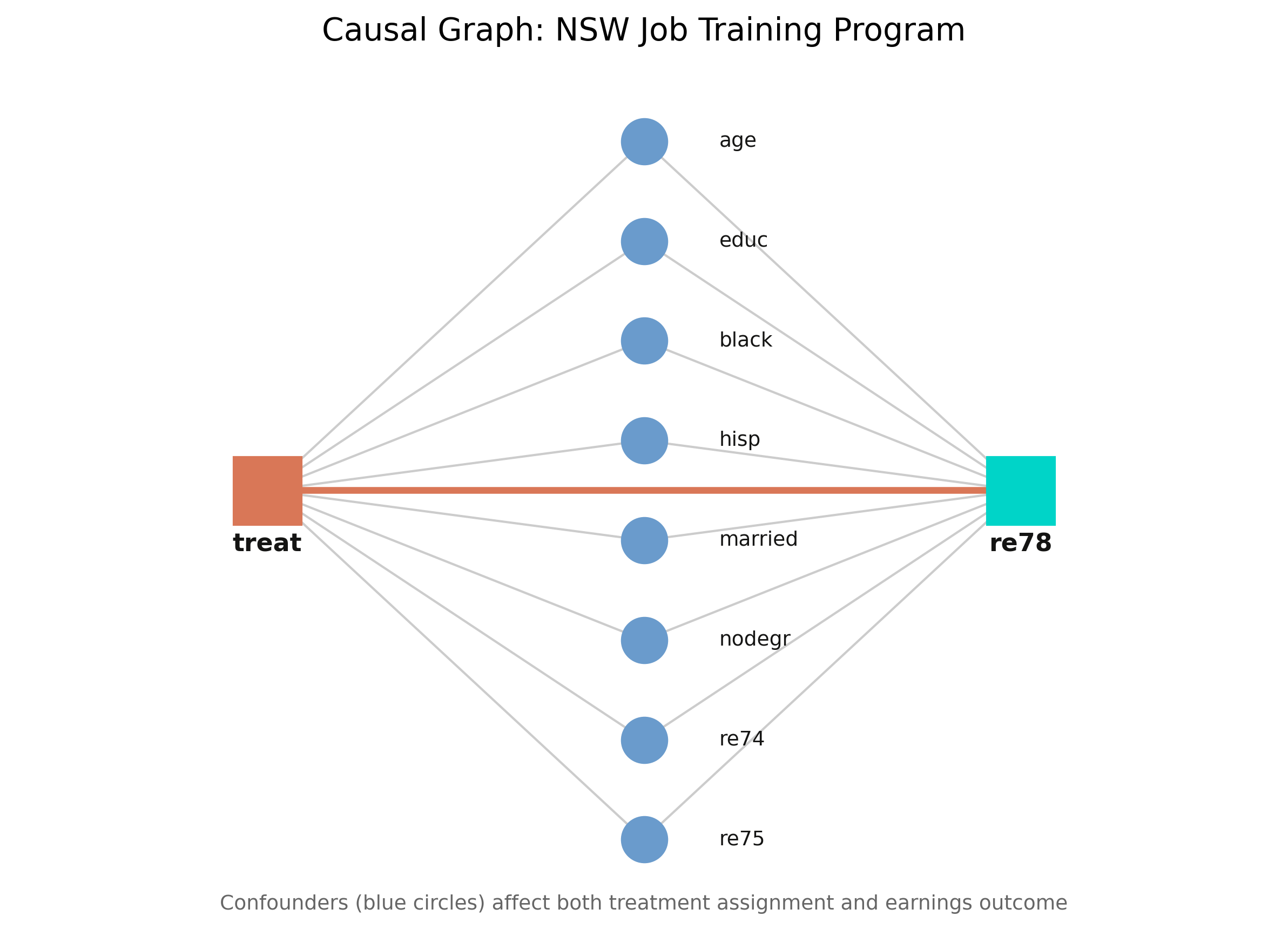
Conditioning on the eight covariates blocks every backdoor path, so the effect is identified — under unconfoundedness (no hidden common cause).
DoWhy checks backdoor, instrumental-variable, and front-door strategies automatically, and returns the formula — not a guess about what to “control for”.
Step 3 — Estimate: three paradigms, one question
Outcome modeling
Models \(E[Y \mid X, T]\)
Regression adjustment
Treatment modeling
Models \(P(T \mid X)\)
IPW · stratification · matching
Doubly robust
Models both
AIPW
If outcome-based and treatment-based methods agree, neither model is badly misspecified — that agreement is the robustness check.
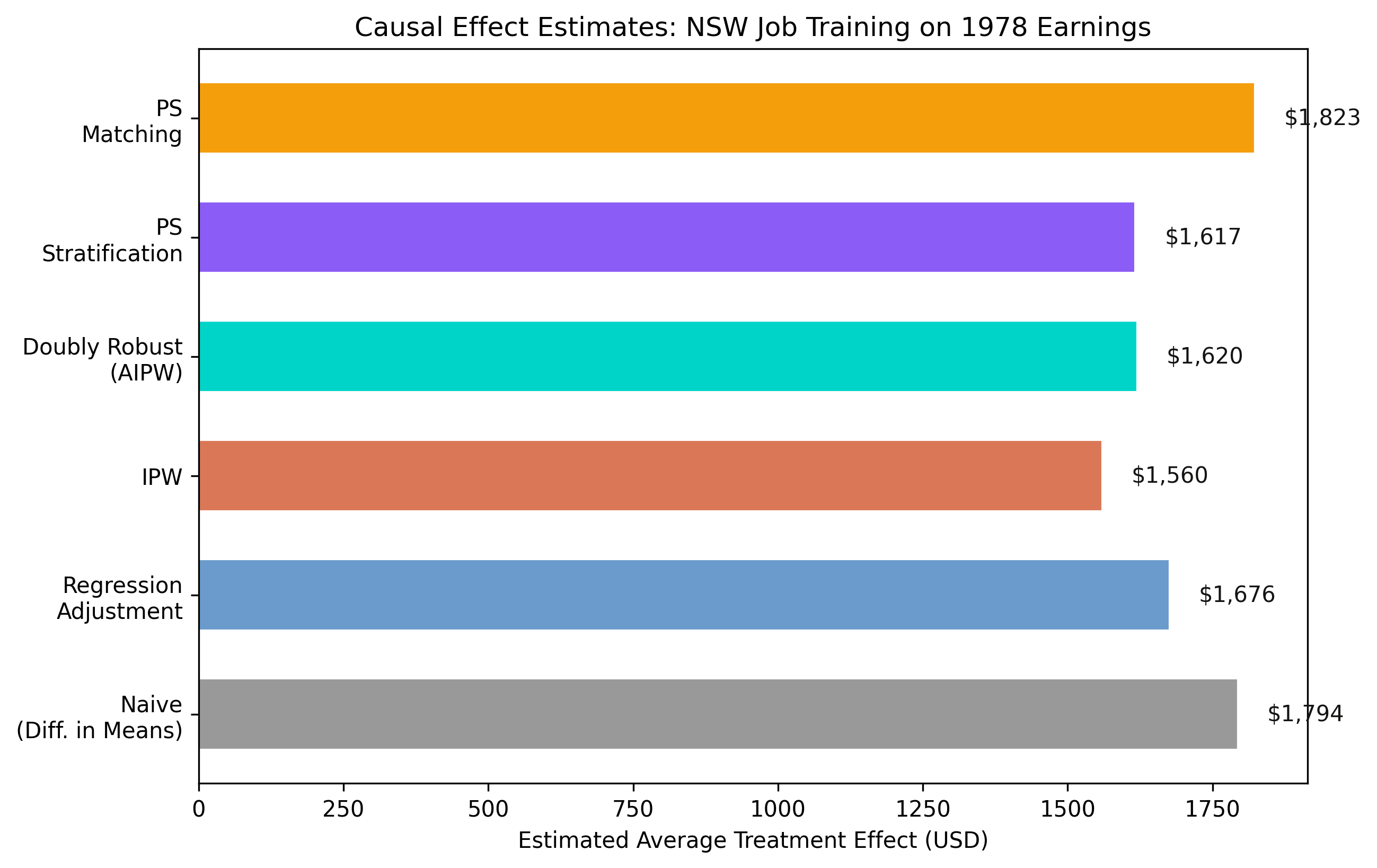
Regression adjustment compares like with like: $1,676
estimate_ra = model.estimate_effect( identified_estimand, method_name="backdoor.linear_regression", confidence_intervals=True) # ATE = $1,676.34
Models \(E[Y \mid X, T]\) and reads the treatment coefficient — the gap at the same covariate values.
IPW re-weights surprising cases by \(1/\hat{e}(X)\): $1,559
Add a fake confounder, drop 20% of the data — the estimate barely moves
Refutation test
New effect
p-value
Reading
Placebo treatment
$62
0.92
effect vanishes
Random common cause
$1,676
0.90
stable with noise
Data subset (80%)
$1,728
0.80
stable across subsamples
Surviving placebo, random-common-cause, and subset tests is evidence, not proof — refutation can falsify, never confirm.
Does machine-picked adjustment make this causal? No — one assumption still carries the weight
Objection. DoWhy automated the workflow, so the estimate must be airtight.
Response. The ATE is identified only under unconfoundedness — no hidden common cause of training and earnings. The four steps make assumptions explicit and testable; they cannot manufacture identification. Here randomization makes unconfoundedness credible; in observational data it is the load-bearing risk.
The training effect is real: ~$1,620, a 34–38% earnings gain
$1,620
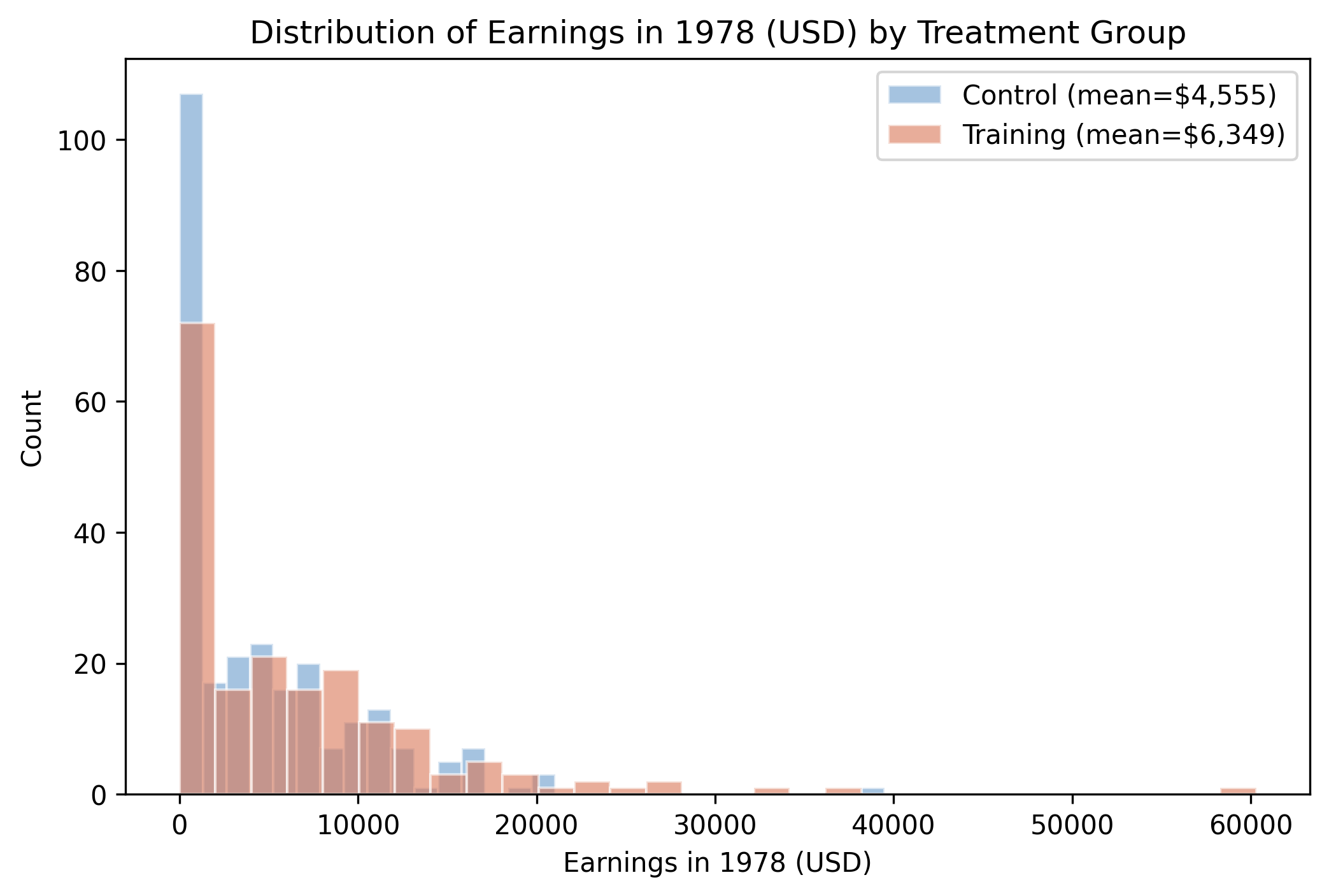
Doubly robust ATE on a control mean of $4,555 · five methods agree · refutation tests survive
State your assumptions, identify the estimand, then let the data — and the refutations — speak.