Same regression, same data — and shock half-lives of 1.5, 9, or 18 years
How much of this year’s employment shock is still visible next year?
The answer is one number: \(\rho\), the coefficient on lagged employment. The estimators in this deck — run on the same 140-firm UK panel — will claim \(\hat\rho = 0.626\), \(0.927\), and \(0.962\).
One of them is defensible. None of them announces which.
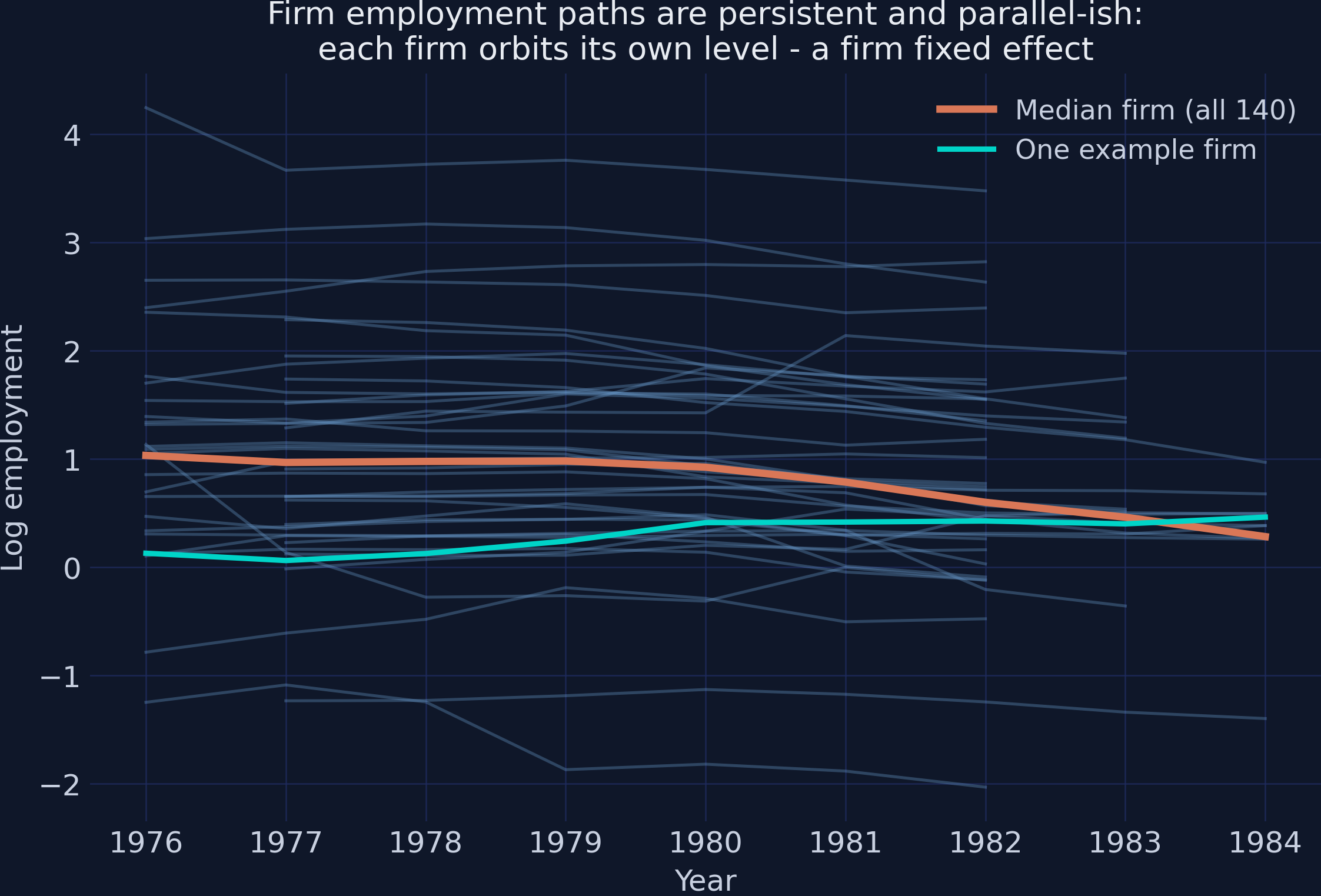
Firms orbit their own levels — a fixed effect and persistence at once
Each blue line is one firm, 1976–1984. Lines are parallel-ish (a firm fixed effect) and smooth (high persistence). The orange median dips after 1980 — the UK recession the year dummies absorb.
The model commits the one sin ordinary panel methods cannot forgive
A lagged dependent variable sits on the right while the firm effect \(\alpha_i\) sits in the error. By construction \(n_{i,t-1}\) depends on \(\alpha_i\) — so the regressor is correlated with the error, no matter how many controls we add.
Where we’re going
Run pooled OLS and fixed effects — two known-direction failures that bracket the truth
Anderson-Hsiao IV: consistent in theory, useless in practice
Difference GMM: passes every printed test, hugs the wrong bound
System GMM: the defensible headline, \(\hat\rho = 0.927\)
The diagnostics decoder — AR(1), AR(2), Hansen, and why p \(\approx\) 1 is a red flag
Instrument proliferation, collapsing, and a digit-for-digit replication check
The Investigation
Act II
Pooled OLS and fixed effects fail in opposite, known directions
Pooled OLS — biased UP
Ignores \(\alpha_i\): it stays in the error
\(n_{i,t-1}\) is positively correlated with \(\alpha_i\)
The lag gets credit for the firm effect’s work
\(\hat\rho = 0.962\) (SE 0.008) — near a unit root
Fixed effects — biased DOWN
Demeaning removes \(\alpha_i\) exactly…
…but the firm mean contains future shocks
Nickell bias, order \(1/T\) — and \(T\) is 7–9 here
\(\hat\rho = 0.626\) (SE 0.052)
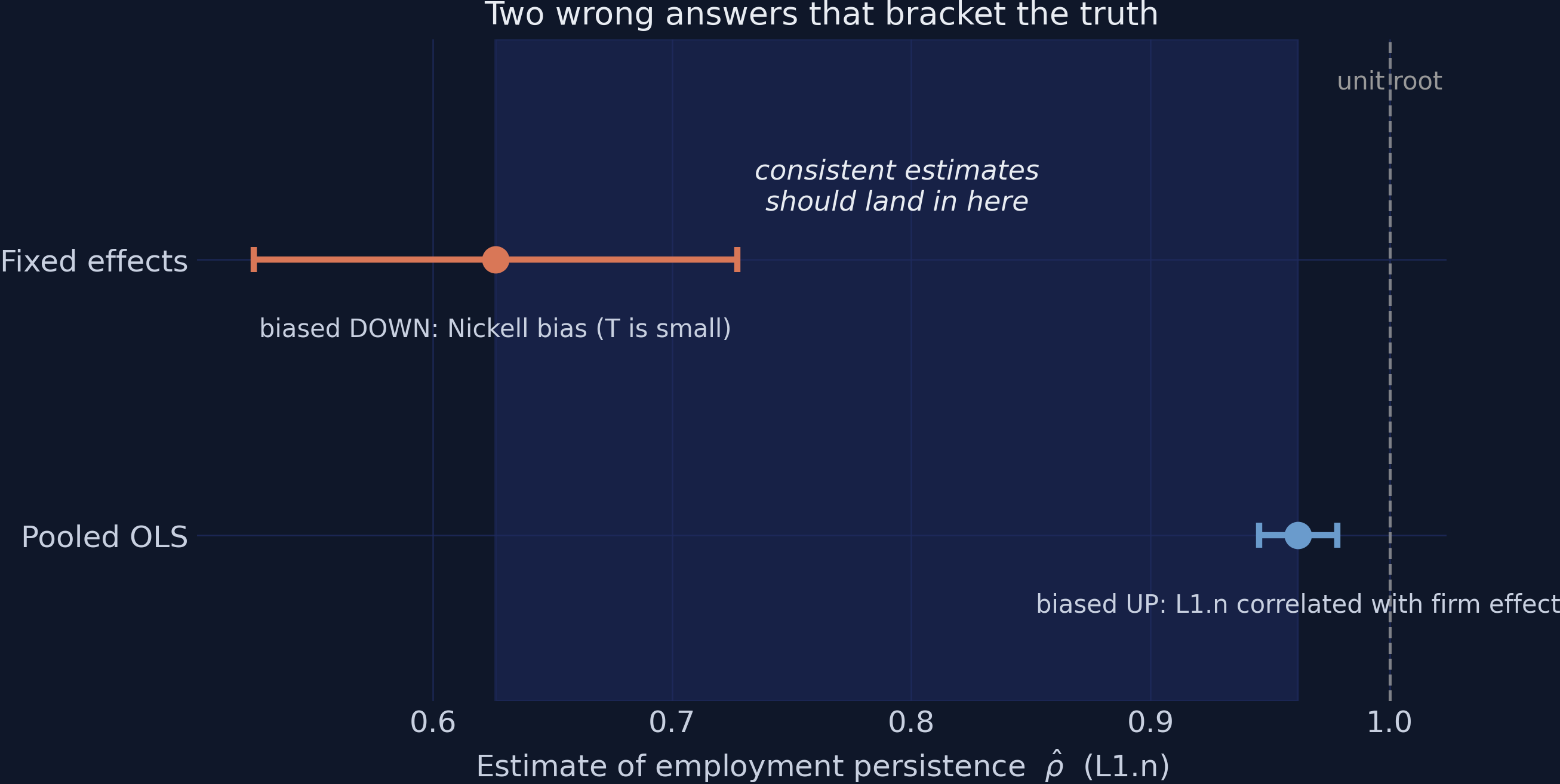
Two wrong answers bracket the truth: any consistent estimate must land in [0.626, 0.962]
Bond’s (2002) bracket: OLS marks the ceiling, FE the floor. The shaded band is the playing field for every estimator that follows.
Anderson-Hsiao IV is consistent — and useless: 1.233 with a CI 1.87 wide
First-difference away \(\alpha_i\), then instrument \(\Delta n_{i,t-1}\) with the level \(n_{i,t-2}\):
Estimate
SE
95% CI
\(\hat\rho\) (Anderson-Hsiao 2SLS)
1.233
0.478
[0.296, 2.170]
The CI contains the whole bracket, the unit root, and explosive dynamics — all at once.
Arellano-Bond: every lag dated \(t-2\) or earlier is a valid instrument
\[E\big[\,n_{i,t-s}\,\Delta\varepsilon_{it}\,\big] = 0 \qquad \text{for all } s \ge 2\]
Employment two or more years ago carries no information about this year’s change in shocks — and the same holds for lagged \(w\) and \(k\). Dozens of moment conditions, combined optimally by GMM.
Two command strings run the whole GMM ladder in pydynpd
Even for a persistent series, last year’s change is informative about this year’s level. The price is one new assumption — mean stationarity: firms’ initial deviations from their steady states must be unrelated to \(\alpha_i\).
Ninety-three percent of an employment shock survives into next year
0.927
system GMM, two-step, 32 collapsed instruments (SE 0.079) — inside the bracket, upper half
The headline’s diagnostics are textbook-clean
Two-step system GMM (collapsed)
\(\hat\rho\) (L1.n)
0.927
SE (Windmeijer)
0.079
Instruments
32 (vs 140 firms)
AR(1) p
0.000 — rejects, as required
AR(2) p
0.994 — clean
Hansen p
0.462 — comfortable middle
Trust, But Verify
Act III
The diagnostics decoder: two of the three tests are read backwards
Test
Correct reading
Headline value
AR(1) in differences
Must reject — rejection is mechanical good news
p = 0.000 ✓
AR(2) in differences
Must not reject — this validates the \(t-2\) instruments
p = 0.994
Hansen J
Two-tailed in spirit — p < 0.05 is invalid; p near 1 is an overwhelmed test
p = 0.462 ✓
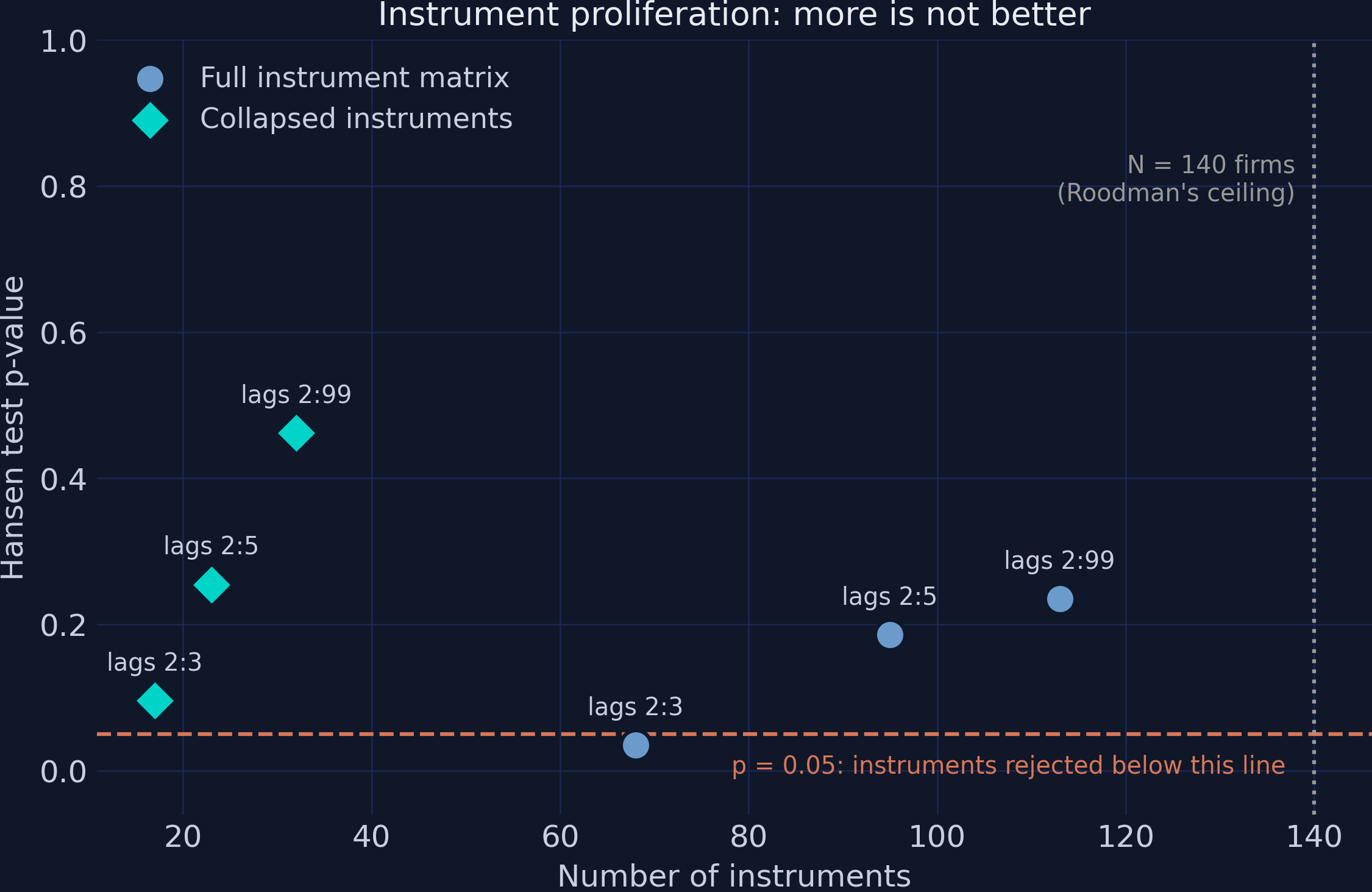
The Hansen p-value responds to the instrument count, not just validity
Lag window
Collapsed
Instruments
\(\hat\rho\)
Hansen p
2:3
no
68
0.956
0.035
2:3
yes
17
0.921
0.096
2:5
no
95
0.935
0.186
2:99
no
113
0.930
0.235
2:99
yes
32
0.927
0.462
Same model six times; only the plumbing changes. Uncollapsed 2:3 is rejected (p = 0.035) while its collapsed twin passes — driven purely by instrument count.
More instruments is not better — proliferation disarms the test that guards you
Hansen p against instrument count: full matrix (steel) vs collapsed (teal), the p = 0.05 rejection line, and the 140-firm Roodman ceiling.
The toolchain replicates the published benchmark digit for digit
Published vignette
Our run
L1.n
0.2710675
0.2710675
Hansen \(\chi^2\)
32.666
32.666
Instruments
42
42
Exact match under a hard assertion — the NumPy-2 compatibility shim perturbs nothing.
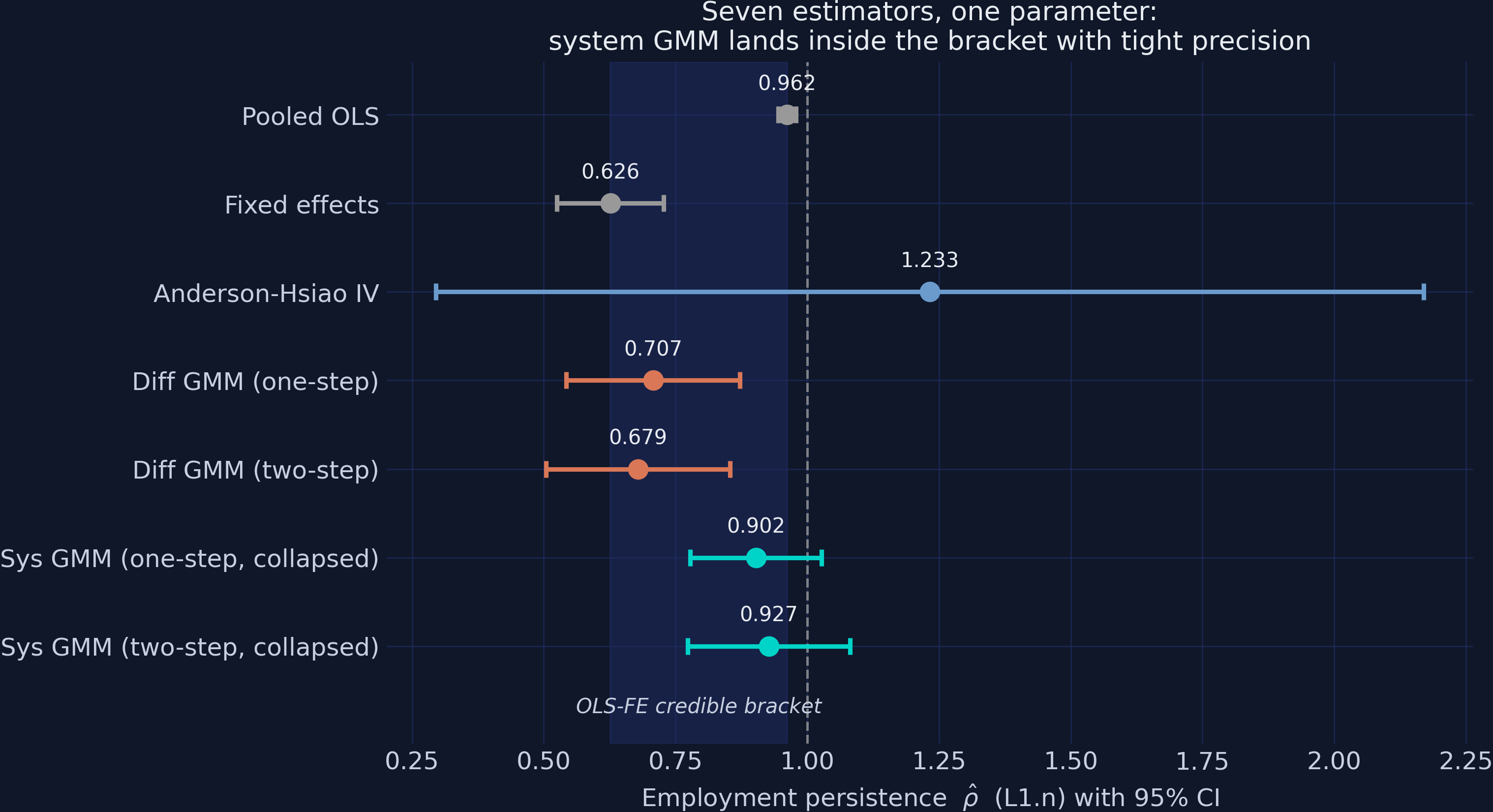
Seven estimators, one parameter — only the workflow identifies the winner
Every estimator with its 95% CI against the shaded OLS–FE bracket. Grey defines the band; blue (Anderson-Hsiao) straddles everything; orange (difference GMM) hugs the floor; teal (system GMM) lands in the upper half.
“Your own CI includes the unit root — why believe 0.927?”
Objection. The headline CI [0.773, 1.081] contains \(\rho = 1\), mean stationarity is untestable, and one common \(\rho\) is imposed on all 140 firms.
Response. All true — which is why the claim is the point estimate and its lower bound, never “employment is stationary.” The estimate survives the bracket check, a 6-cell proliferation grid (range 0.921–0.956), clean AR(2)/Hansen, and an exact replication — and the mean-stationarity price is stated out loud, not hidden.
The dynamic-panel checklist you take home
Run OLS and FE first — record the bracket; they are the measuring stick
A difference-GMM estimate hugging the FE bound is a weak-instrument symptom — passing Hansen and AR(2) does not clear it
Prefer system GMM when persistence is high — and name the mean-stationarity assumption you are buying
AR(1) must reject; AR(2) must not; read Hansen two-tailed
Collapse instruments and report the count relative to the number of groups
Replicate a published benchmark before trusting novel numbers
No single p-value separates 0.927 from 0.679 — the bracket-plus-diagnostics workflow does.