where \(\tilde x_1\) is the residual of \(x_1\) (coupons) regressed on \(x_2\) (income), and \(\tilde y\) is the residual of \(y\) (sales) regressed on \(x_2\).
Remove income from coupons, remove income from sales, then regress the leftovers. Same \(\hat\beta_1\).
Three lines of statsmodels reproduce the multivariate coefficient
# residualize each variable with respect to incomedf["coupons_tilde"] = smf.ols("coupons ~ income", df).fit().residdf["sales_tilde"] = smf.ols("sales ~ income", df).fit().resid# regress residual sales on residual coupons (no intercept)fwl = smf.ols("sales_tilde ~ coupons_tilde - 1", df).fit()
Residuals are mean-zero, so we drop the intercept. The coefficient on coupons_tildeis the controlled effect.
Residualize-both reproduces +0.2673 exactly — and recovers the SE
FWL step
Coupons coef.
SE
p
Step 1 — residualize \(x_1\) only
+0.2673
1.271
0.834
Step 2 — residualize both
+0.2673
0.118
0.028
Same coefficient to four decimals; residualizing the outcome too restores the SE to match full OLS (0.120).
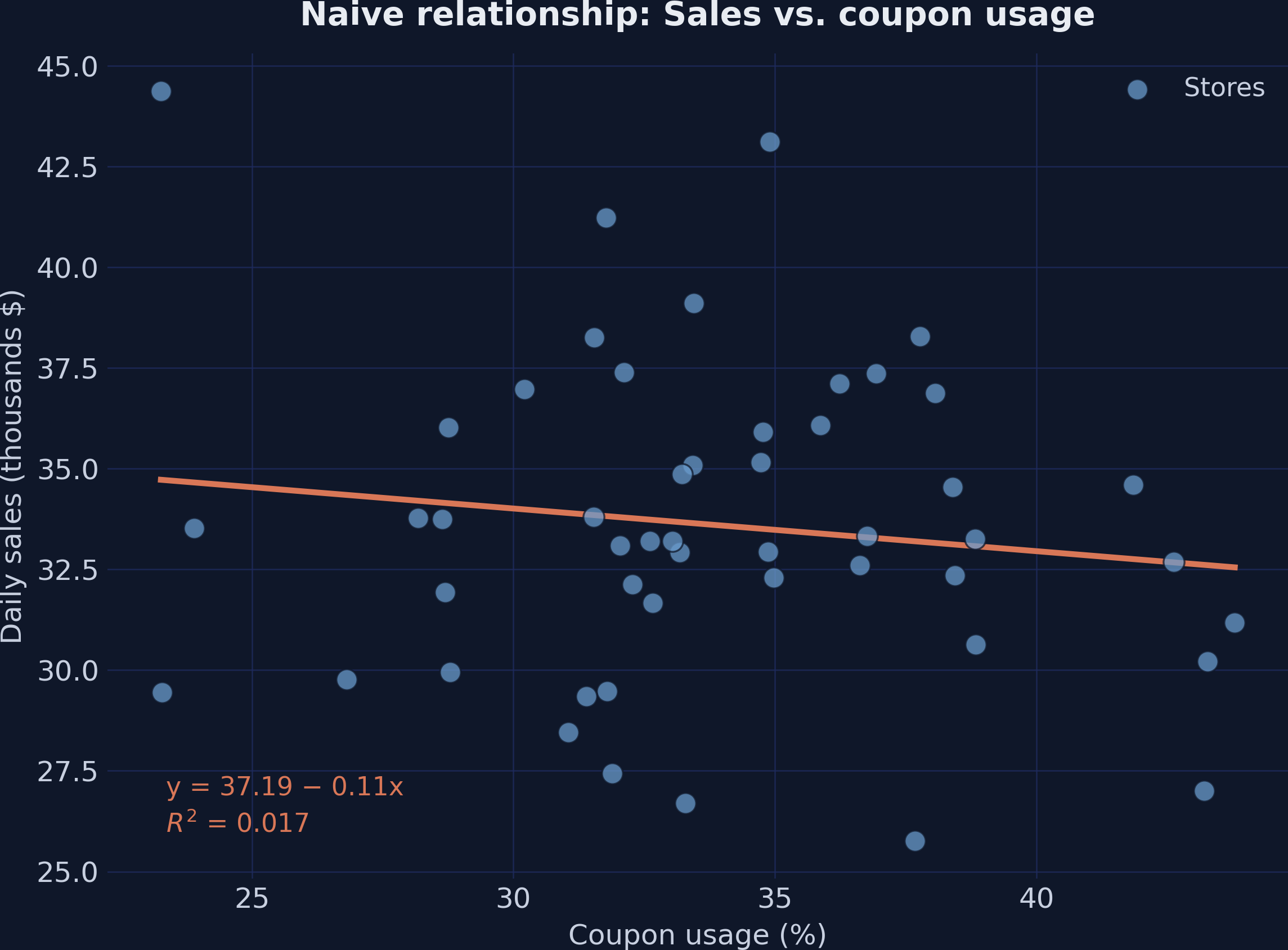
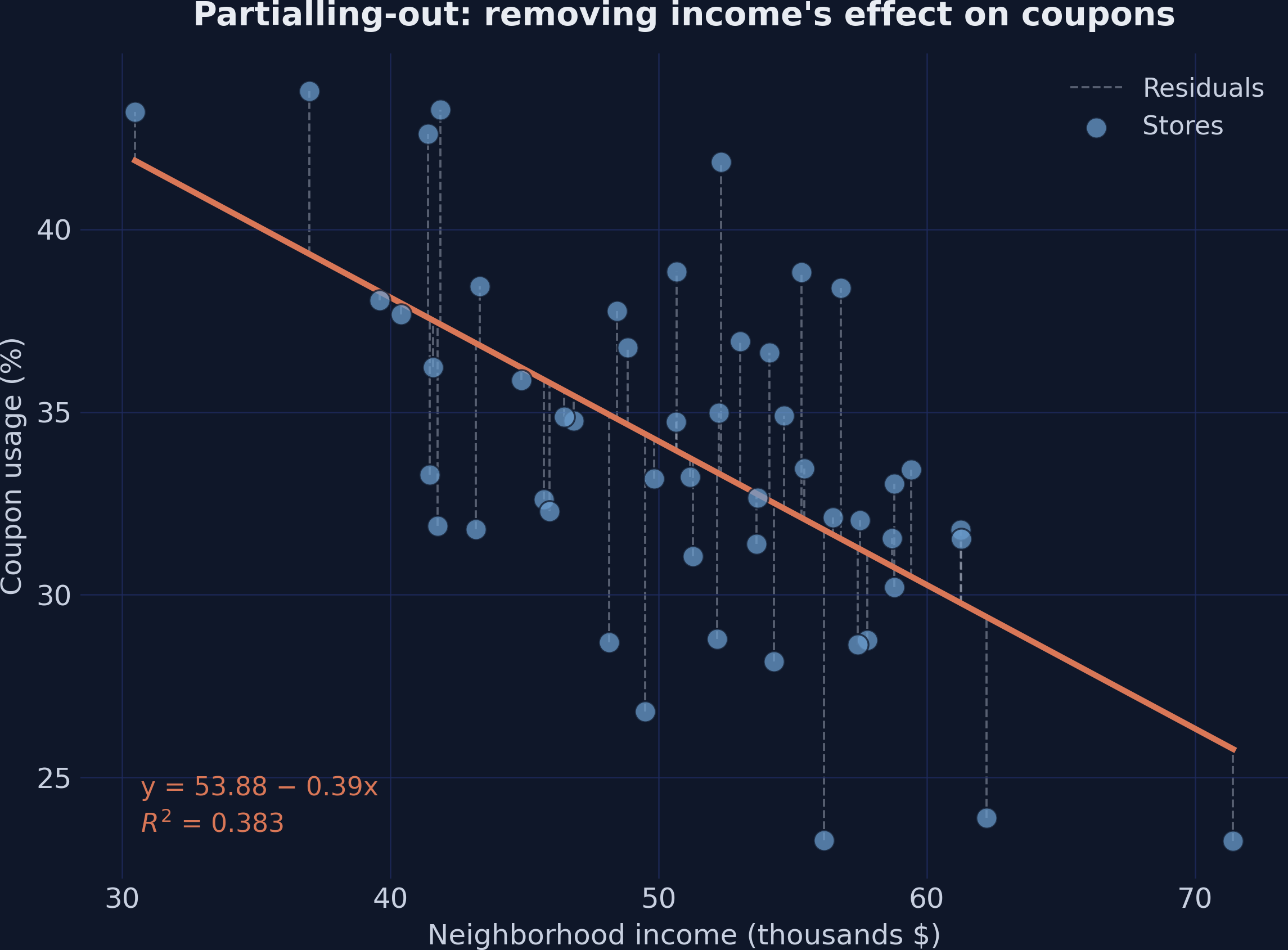
Partialling-out, drawn: the residuals are coupon variation income can’t explain
Coupon usage vs. income; the orange line is the income→coupons fit, dashed lines are the residuals each store keeps.
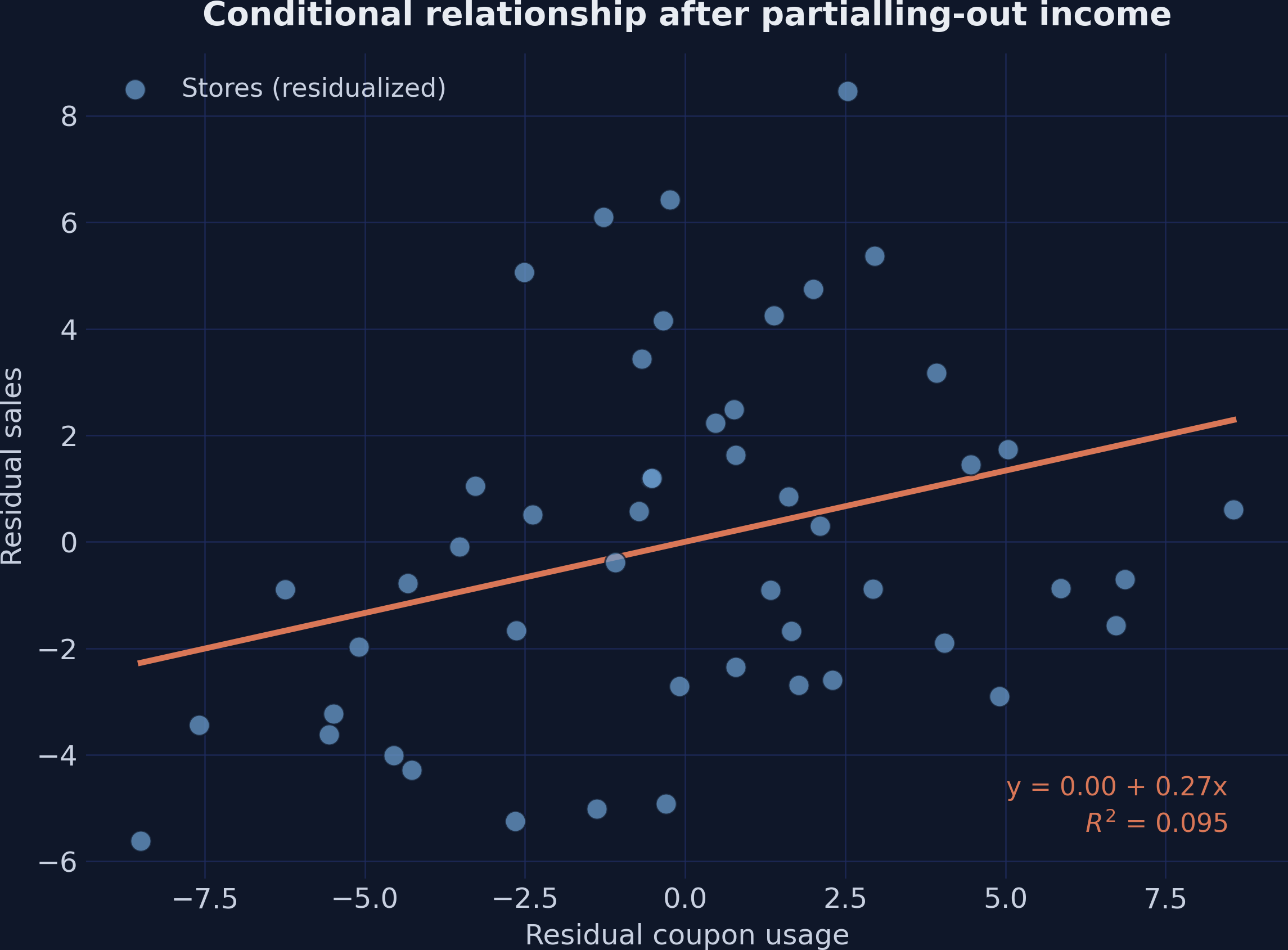
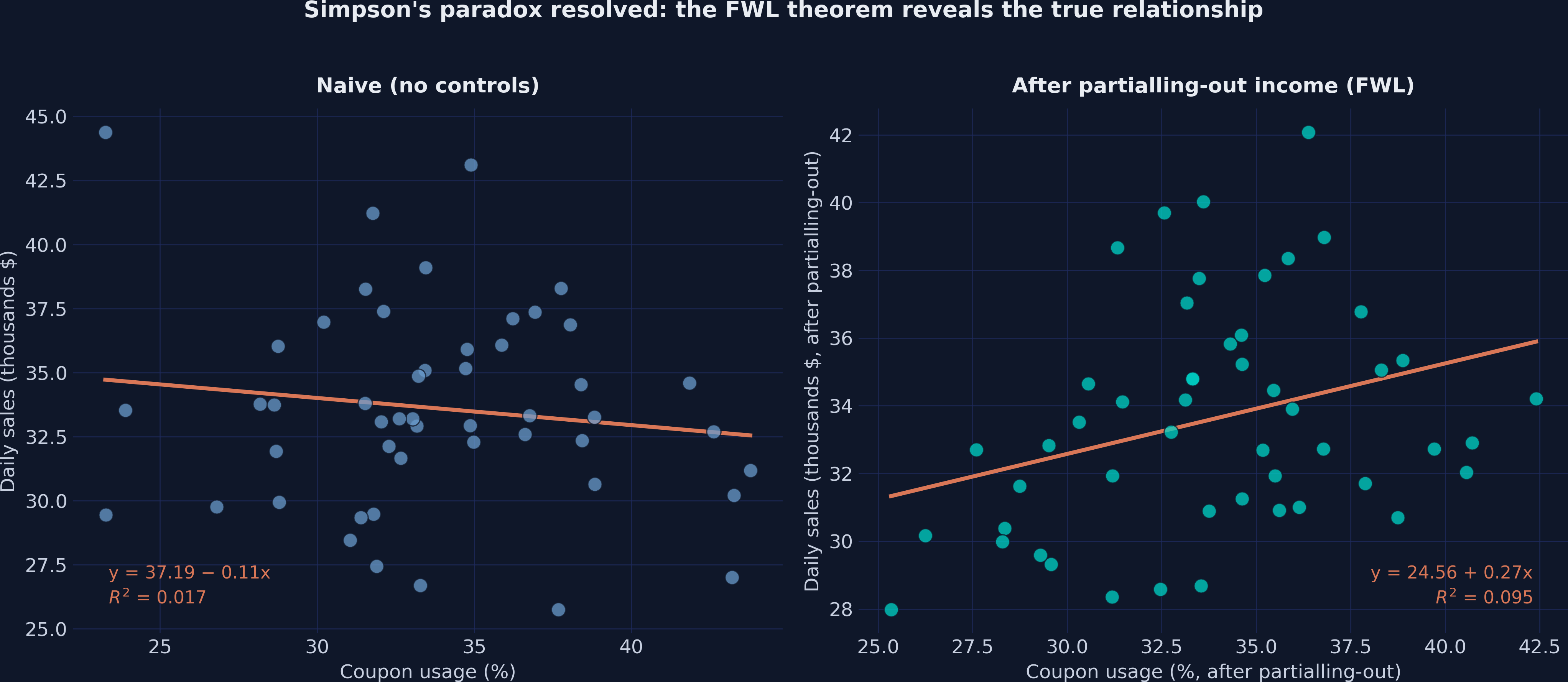
The hidden positive relationship the table couldn’t show you
Residualized sales vs. residualized coupons. With income removed from both, the slope is the +0.267 conditional effect.
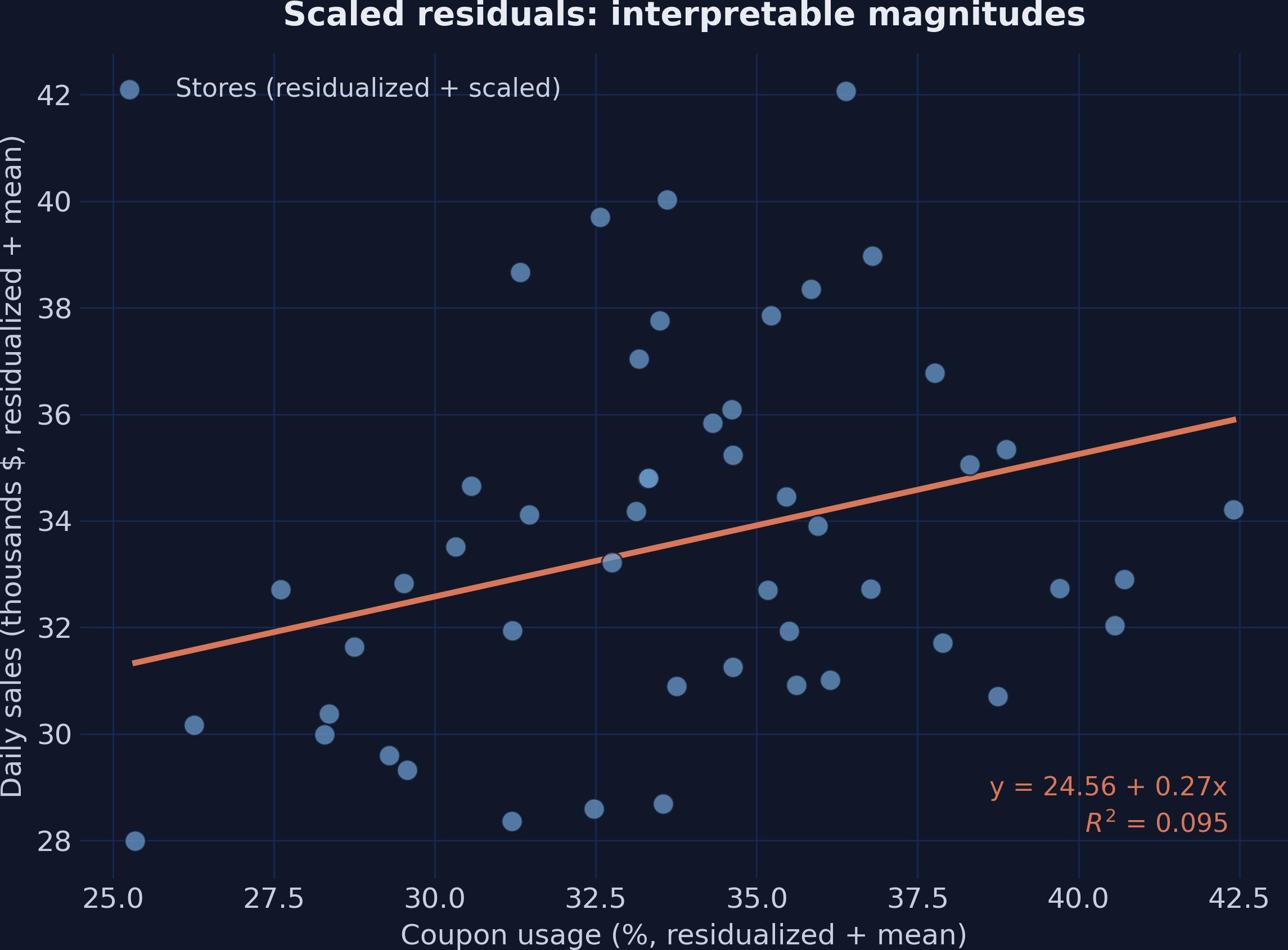
Adding the means back keeps the slope but restores readable units
Same residual scatter shifted by the sample means — axes now read ~34% coupons and ~$33.6K sales, slope still +0.267.
FWL scales: two controls, same identity, +0.2706
Model
Coupons coef.
SE
p
Full OLS (+ income + day)
+0.2706
0.119
0.028
FWL (+ income + day)
+0.2706
0.116
0.023
Partial out income and day-of-week from both sides — identical coefficient. The theorem holds for any number of controls.
The Resolution
Act III
After partialling-out income, coupons raise sales by +0.267
+0.267
\(\hat\beta_1\) on coupons, full OLS = FWL (SE 0.118) · matches the true +0.200 within finite-sample noise
Simpson’s paradox, resolved: the slope flips from −0.106 to +0.267
Left: naive negative slope. Right: positive slope after partialling-out income. Same 50 stores.
Six estimators, one coefficient: FWL is an identity, not an approximation
Method
Coupons coef.
SE
p
Naive OLS (no controls)
−0.1059
0.116
0.365
Full OLS (+ income)
+0.2673
0.120
0.031
FWL residualize \(x\) only
+0.2673
1.271
0.834
FWL residualize both
+0.2673
0.118
0.028
Full OLS (+ income + day)
+0.2706
0.119
0.028
FWL (+ income + day)
+0.2706
0.116
0.023
Does FWL make this causal? No — it visualizes, it does not identify
Objection. Residualizing on income looks like a trick that manufactures a causal effect.
Response. FWL is pure algebra — it only reproduces what OLS already computes. The causal reading needs one assumption: income is the only confounder. FWL pictures that adjustment; it cannot certify it.
FWL is Double Machine Learning with a linear mop
FWL (here)
residualize \(y\), \(d\) with OLS
regress residual \(y\) on residual \(d\)
exact for linear confounding
Double ML
residualize \(y\), \(d\) with ML (forest, lasso)
regress residual \(y\) on residual \(d\)
handles non-linear, high-dim controls
Same residualize-then-regress logic; swap OLS for a flexible learner and you get a debiased causal estimate.
Don’t read the coefficient — read the partialled-out scatter.