Random Forest Regression
How much development signal hides in a satellite image?
Nagoya University (GSID)
July 8, 2026
Predictions cluster near the mean — the model knows the middle, not the edges
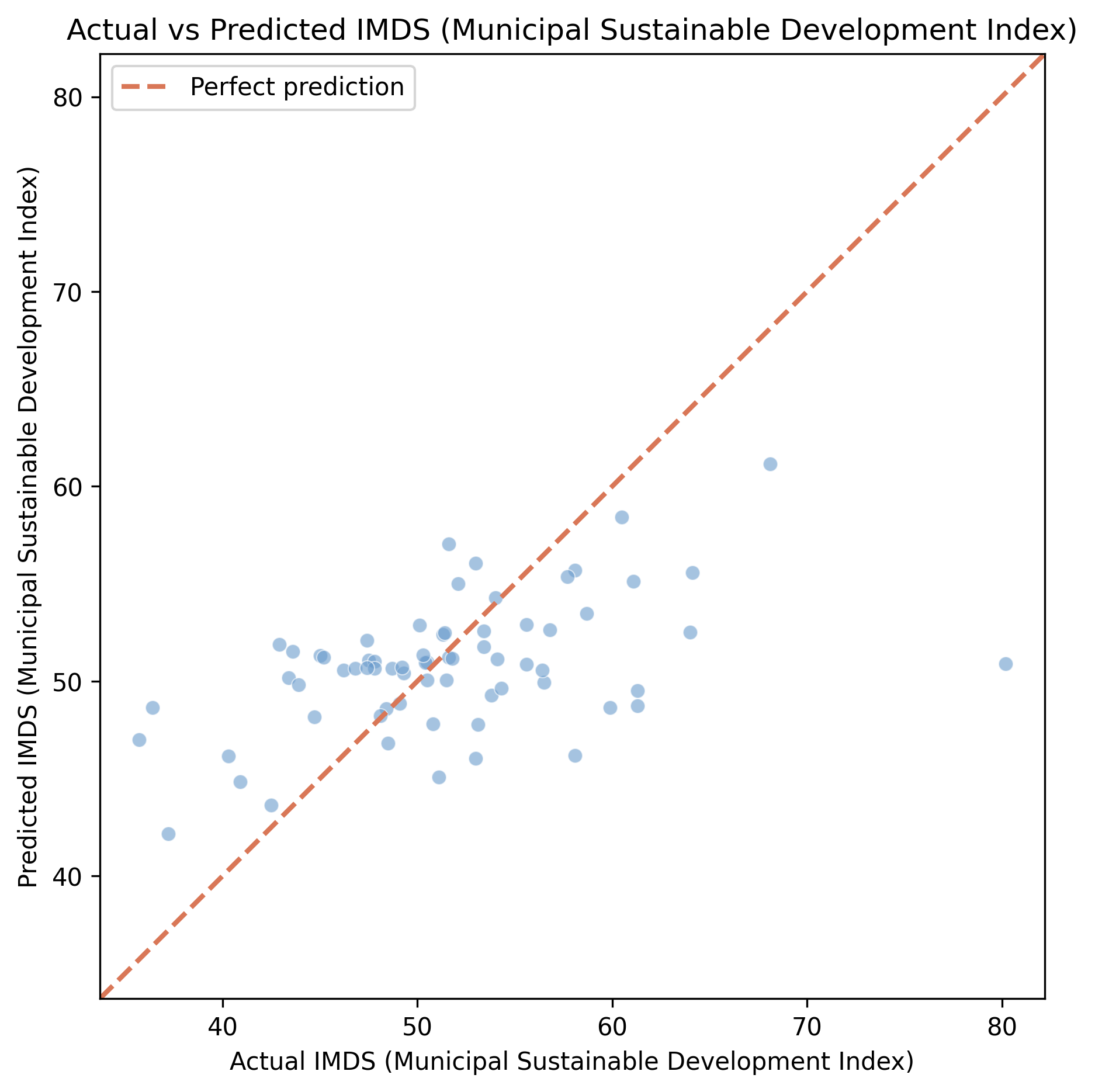
Out-of-fold predicted vs actual IMDS for all 339 municipalities, colored by cross-validation fold; the dashed line is perfect prediction.
The target is tightly bunched: most towns score between 47 and 55
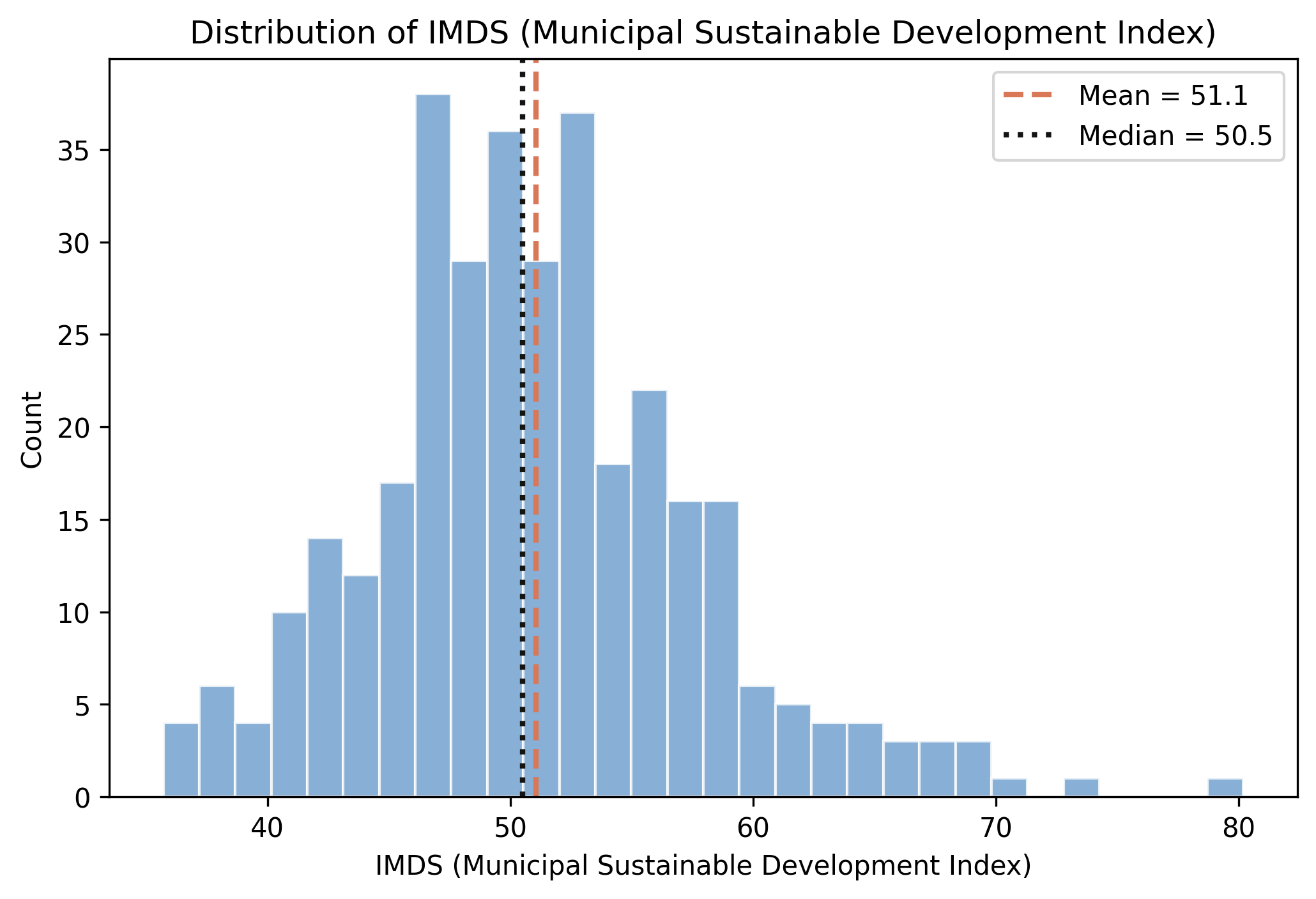
Distribution of IMDS across 339 municipalities; dashed = mean (51.1), dotted = median (50.5).
No single embedding is a smoking gun — the best correlation is only 0.37
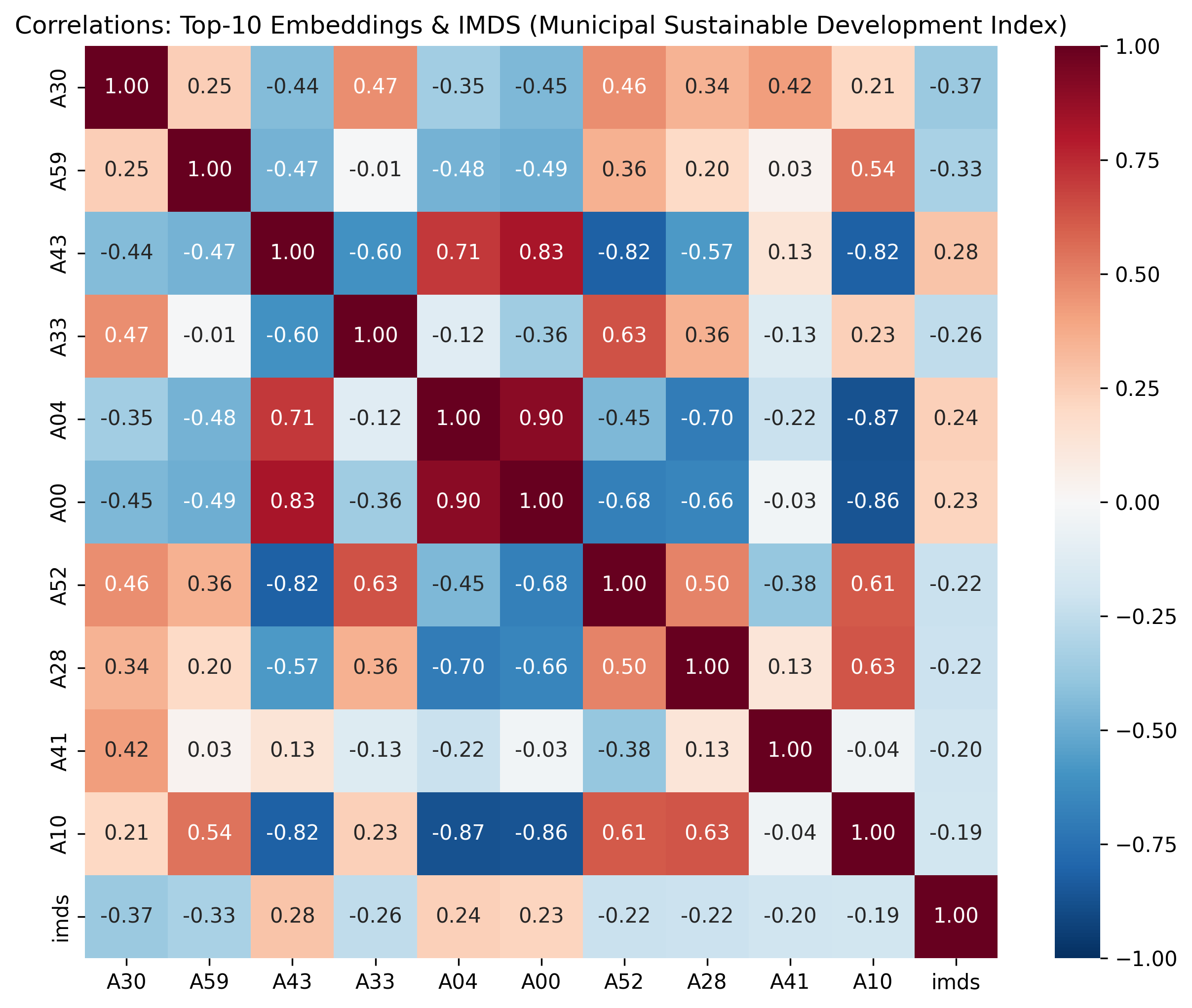
Correlation matrix: the ten embedding dimensions most correlated with IMDS.
Report the standard deviation: the model’s quality swings fold to fold
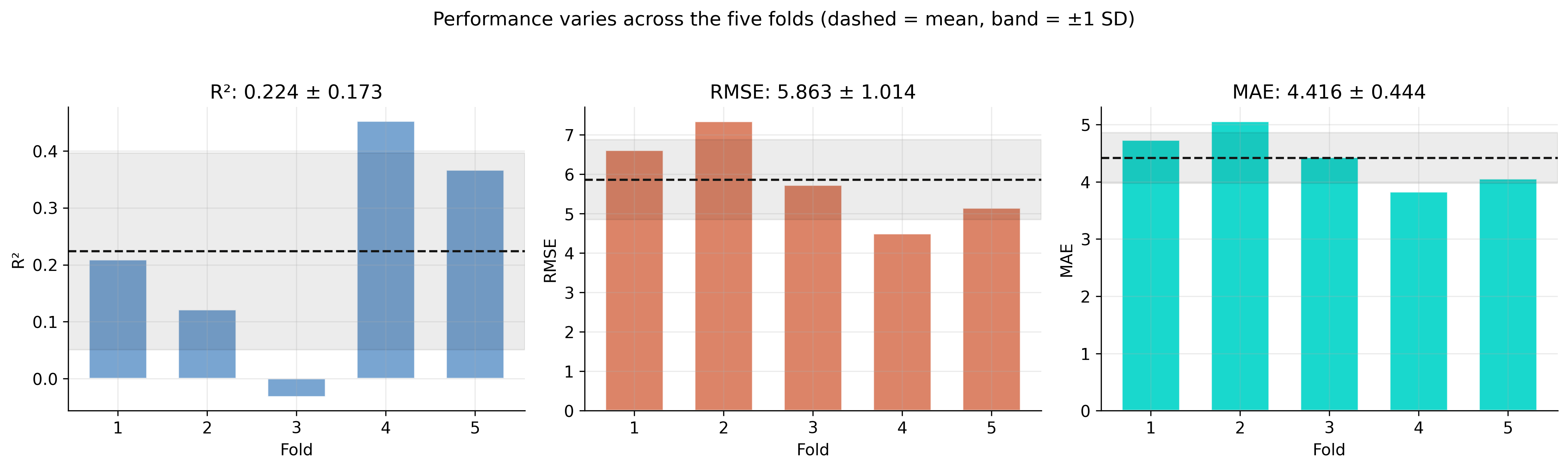
Per-fold R-squared, RMSE, and MAE; dashed line = mean, shaded band = ±1 standard deviation.
A30 carries the signal — shuffling it alone costs more R-squared than the model has
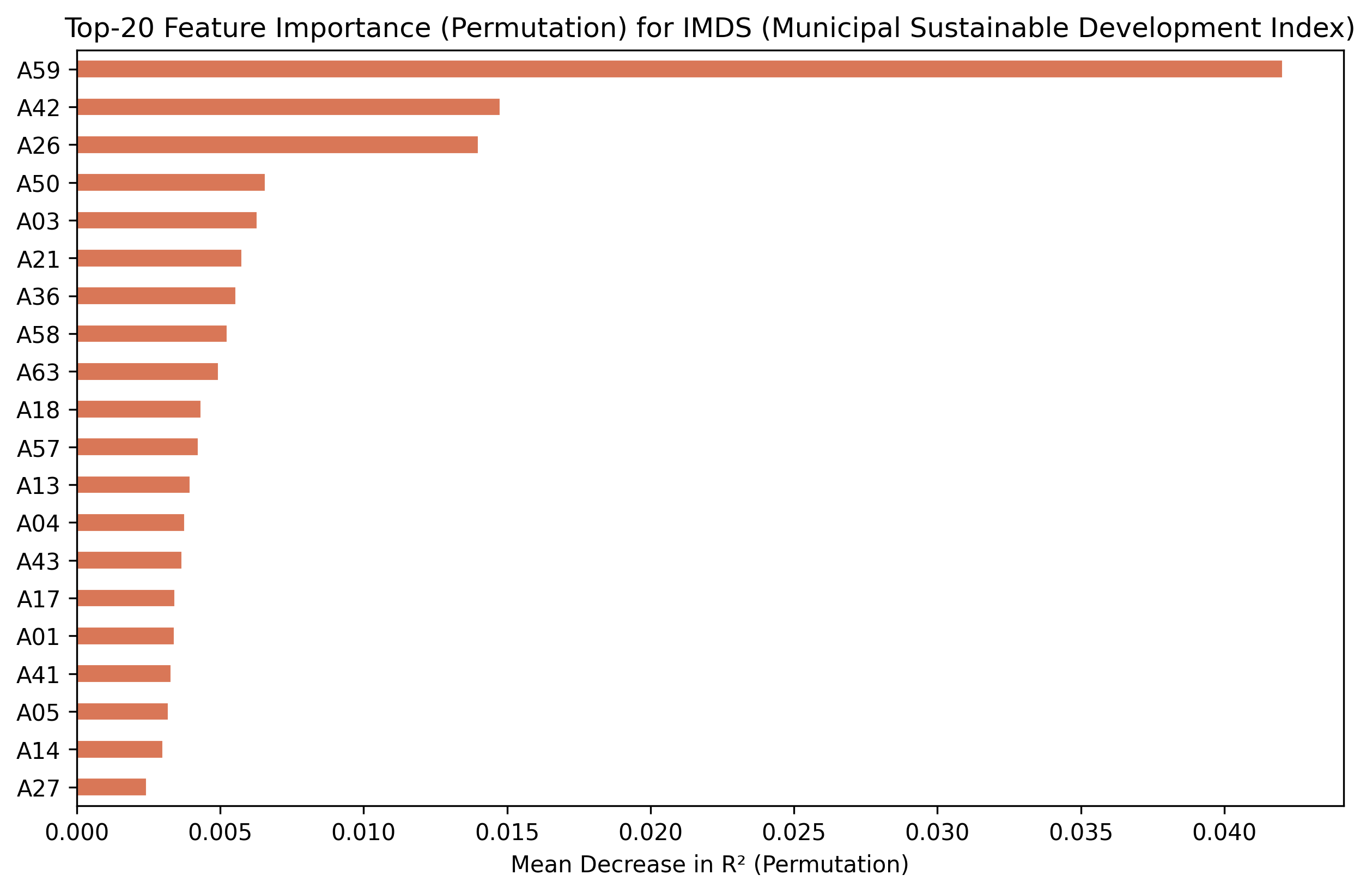
Top-20 embedding dimensions by permutation importance (drop in R-squared when a feature is shuffled).
The relationships are non-linear thresholds — which is why a tree beats a line
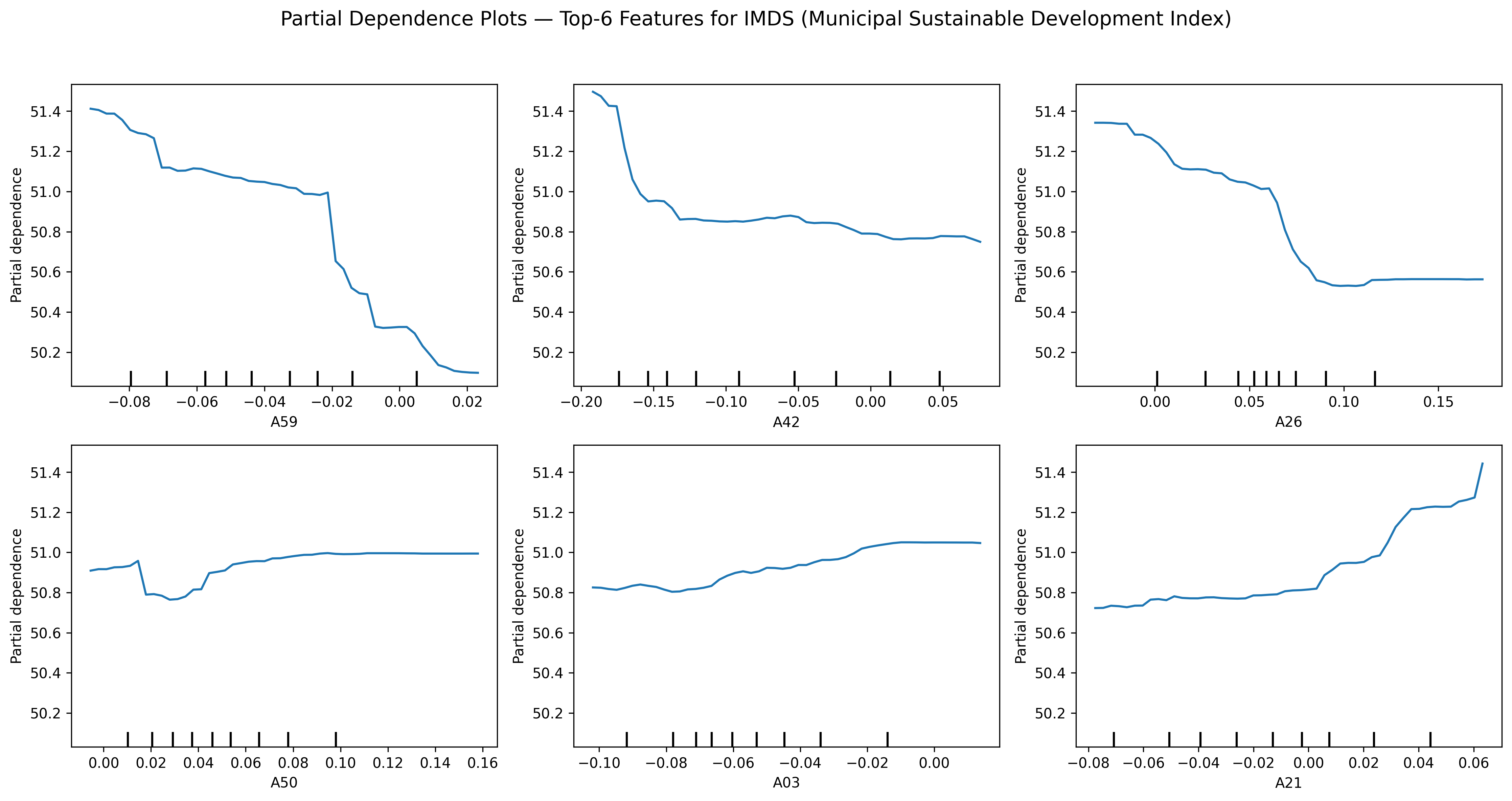
Partial dependence for the top-6 embeddings: sharp rises then plateaus, not straight lines.
Predictions match the center of the distribution — but only half its spread
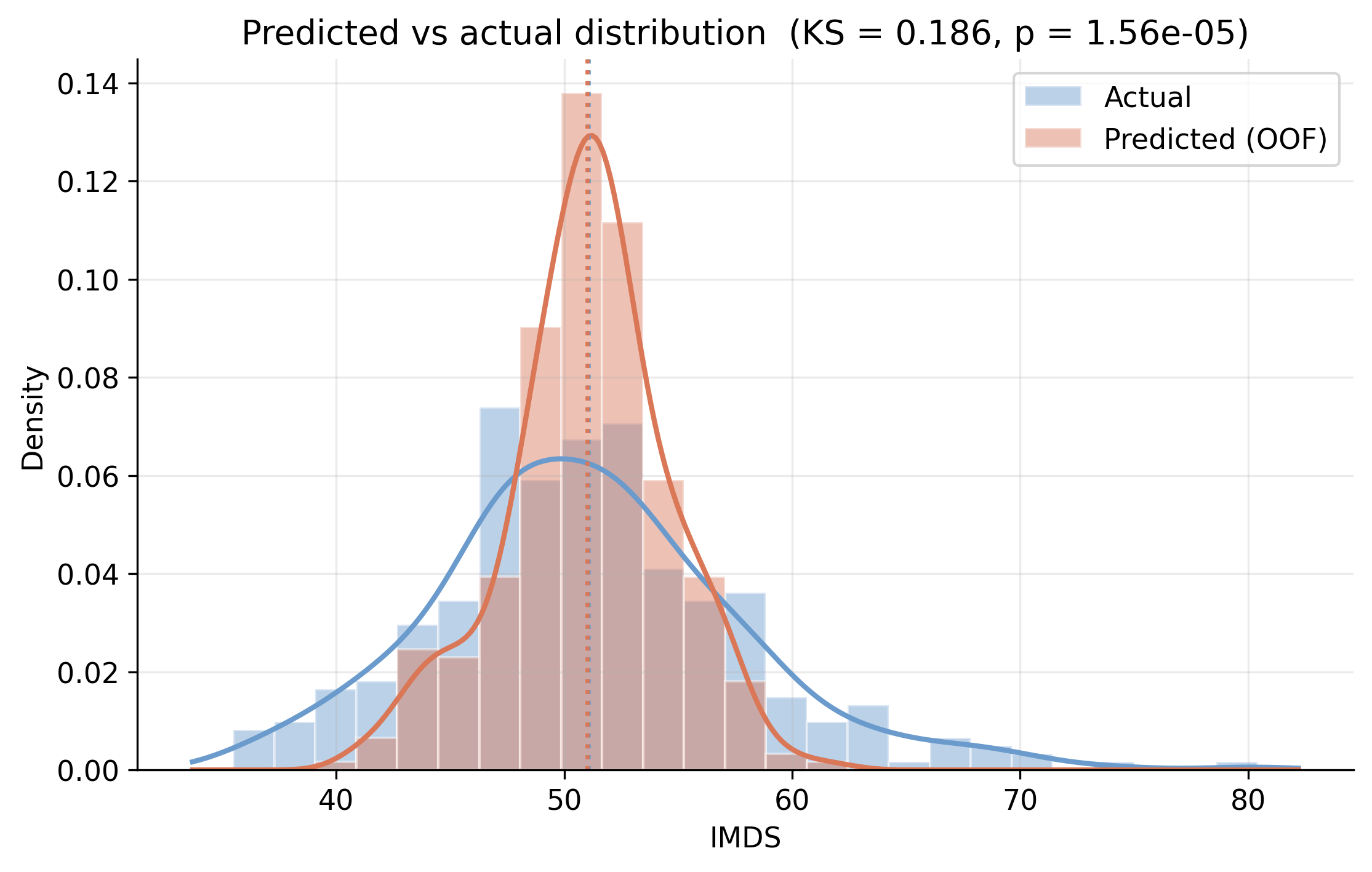
Density of actual IMDS vs out-of-fold predictions; a Kolmogorov–Smirnov test rejects equal distributions.
The model is typically off by 4.4 IMDS points — and worst at the high end
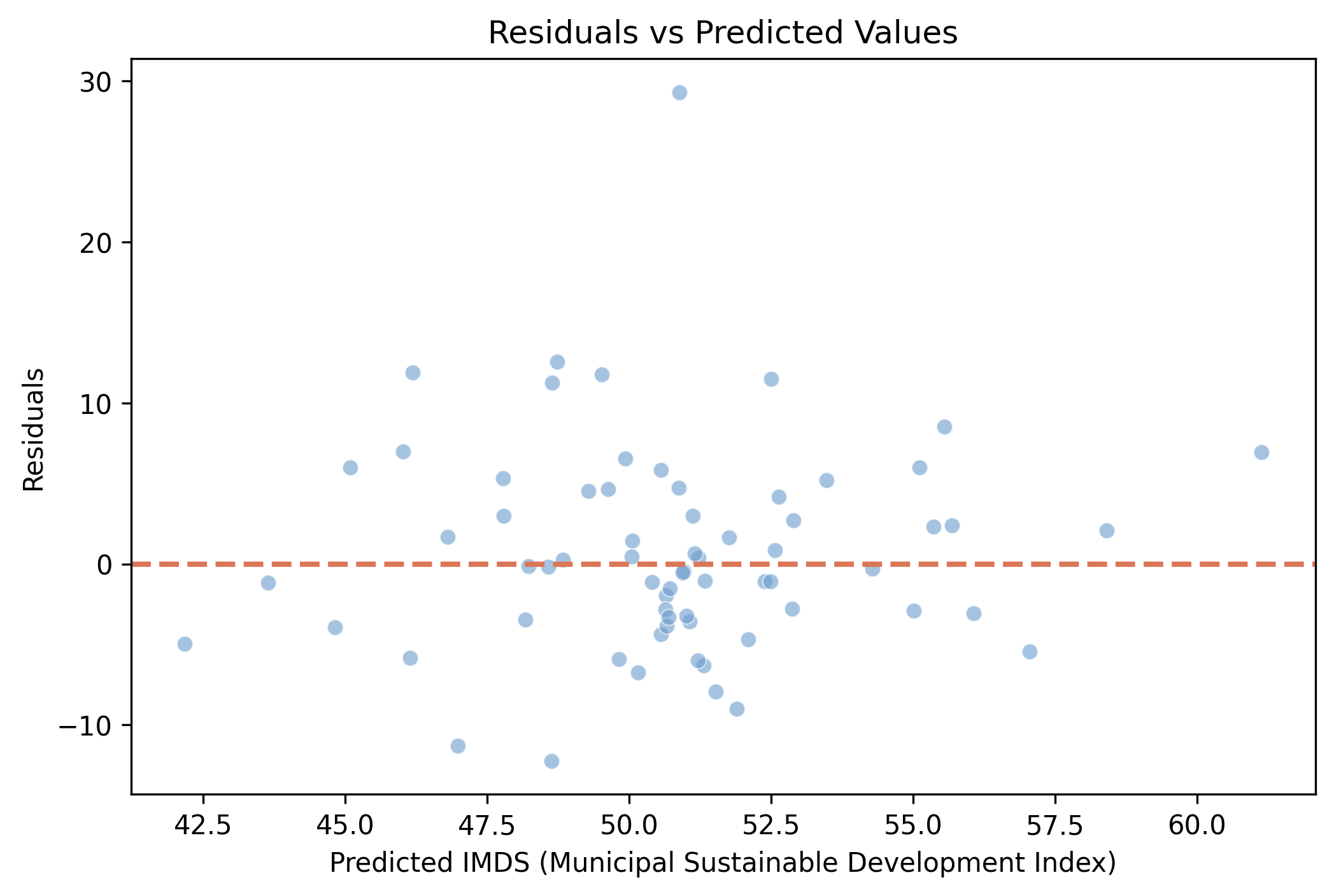
Out-of-fold residuals versus predicted IMDS, colored by fold: centered on zero but tilting up where the under-predicted big cities sit.
Does tuning rescue it? Grid, random, and Optuna all lift R-squared by < 0.03
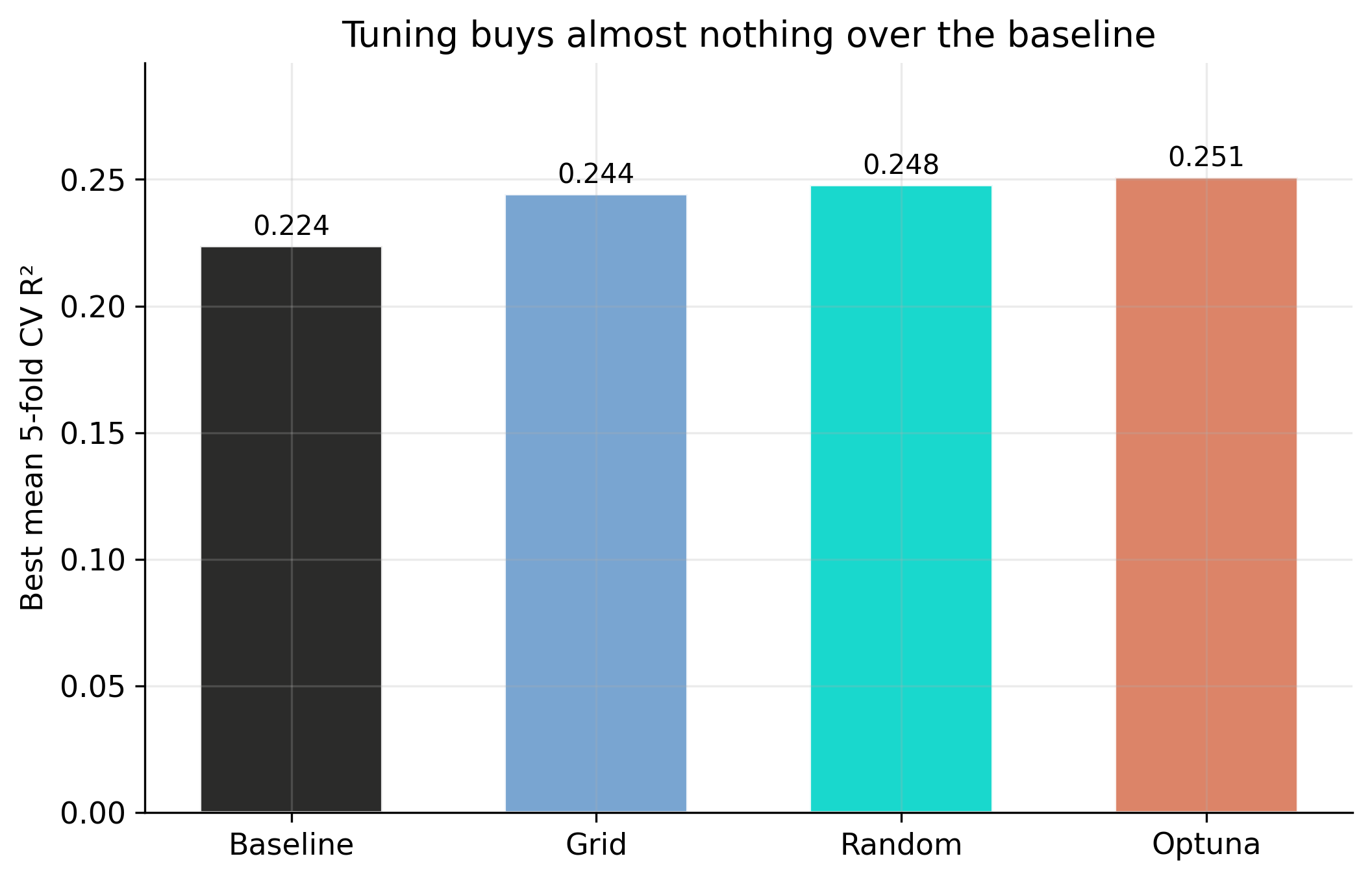
Best cross-validated R-squared: baseline vs grid search, random search, and Optuna (Appendix B).
The methods rank as theory predicts — Optuna ≥ random ≥ grid — but every gain is smaller than the 0.17 fold-to-fold noise.