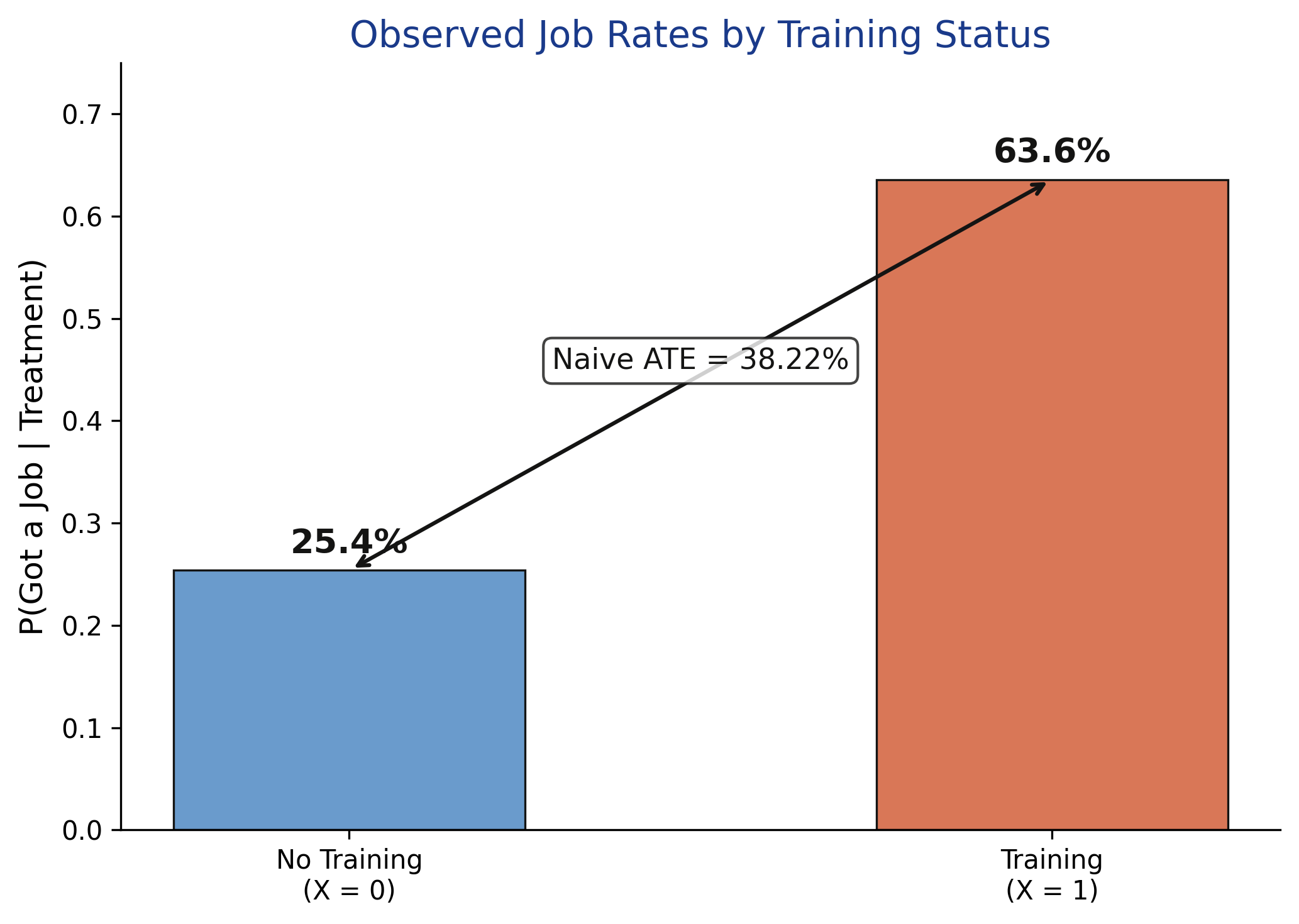
We observe the first term; the counterfactual \(E[Y(1)\mid X{=}0]\) is unknown but, for a binary \(Y\), lies in \([0,1]\). Plug in the worst and best cases.
No parametric model, no exclusion restriction — only “the unseen counterfactual is a probability.”
Three lines of arithmetic give the worst-case ATE interval
scenario = BinaryConf(X, Y) # confounded binary scenariomanski = scenario.ATE.manski() # closed-form, no assumptions# manual worst/best case for the unseen counterfactual:E_Y1 = (P_Y1_X1*P_X1 +0*P_X0, P_Y1_X1*P_X1 +1*P_X0)ATE_lower, ATE_upper = E_Y1[0] - E_Y0_upper, E_Y1[1] - E_Y0_lower
CausalBoundingEngine matches the hand computation exactly — and in under a millisecond.
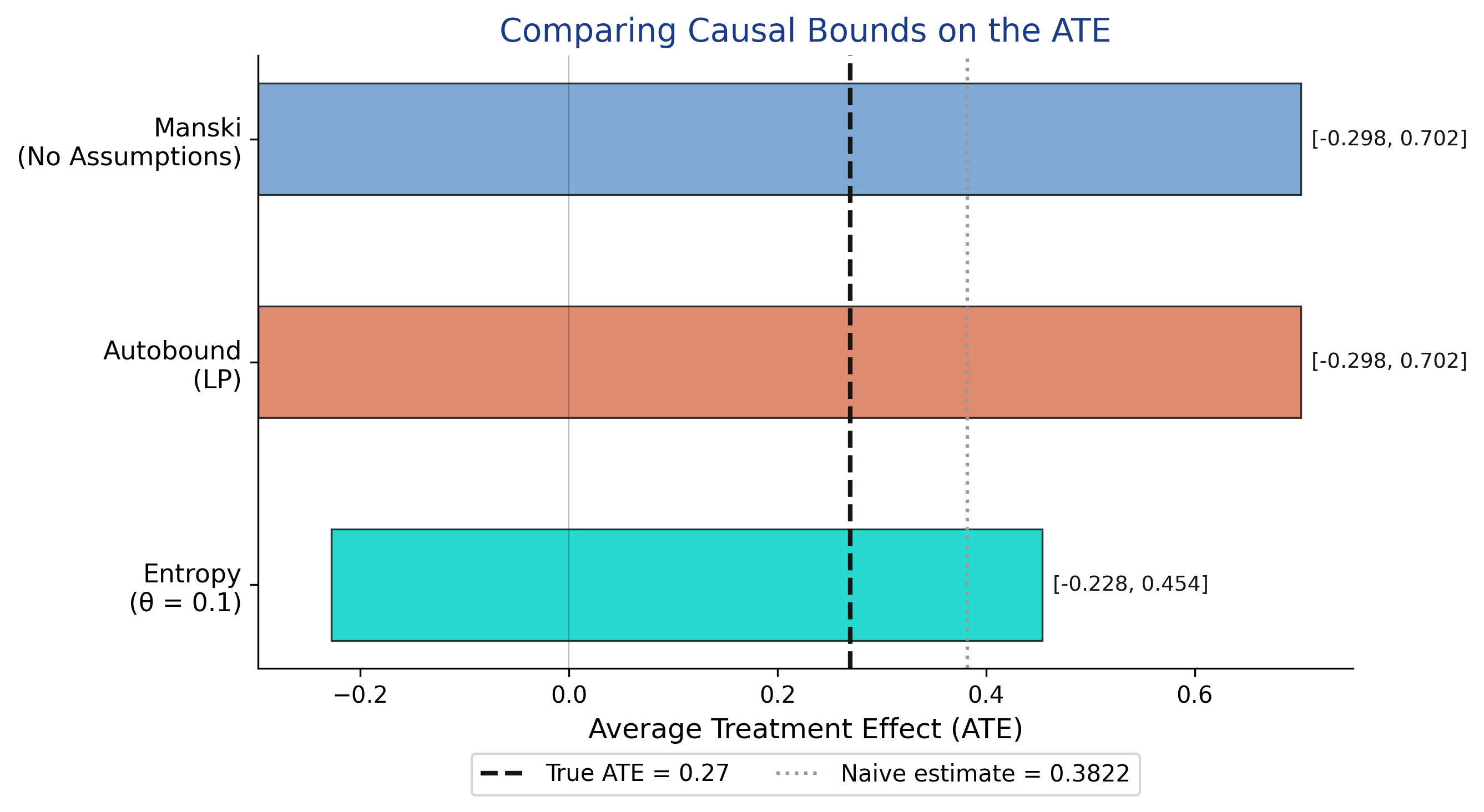
No-assumption bounds span zero: the sign of the effect is undetermined
[−0.30, 0.70]
Manski ATE bounds · width exactly 1.0 · the true ATE (0.27) sits inside
Linear programming confirms Manski is already sharp — it cannot be beaten
Method
Lower
Upper
Width
Manski (no assumptions)
−0.2980
0.7020
1.0000
Autobound (LP)
−0.2980
0.7020
1.0000
Autobound solves an optimization and lands on the same interval — the worst-case distributions are genuinely valid.
A mild entropy cap on the confounder shrinks the interval by 32%
\[H(U \mid X, Y) \leq \theta\]
Bound how surprising the hidden confounder may be. At \(\theta = 0.1\) the ATE tightens to \([-0.2279,\ 0.4540]\) — width 0.6819.
Entropy is a middle ground: more than “nothing” (Manski), less than “no confounders” (DoubleML).
All three ATE bounds bracket the truth; only their width differs
Manski and autobound coincide at width 1.0; entropy (θ=0.1) is 32% narrower; the naive estimate sits to the right of the true ATE.
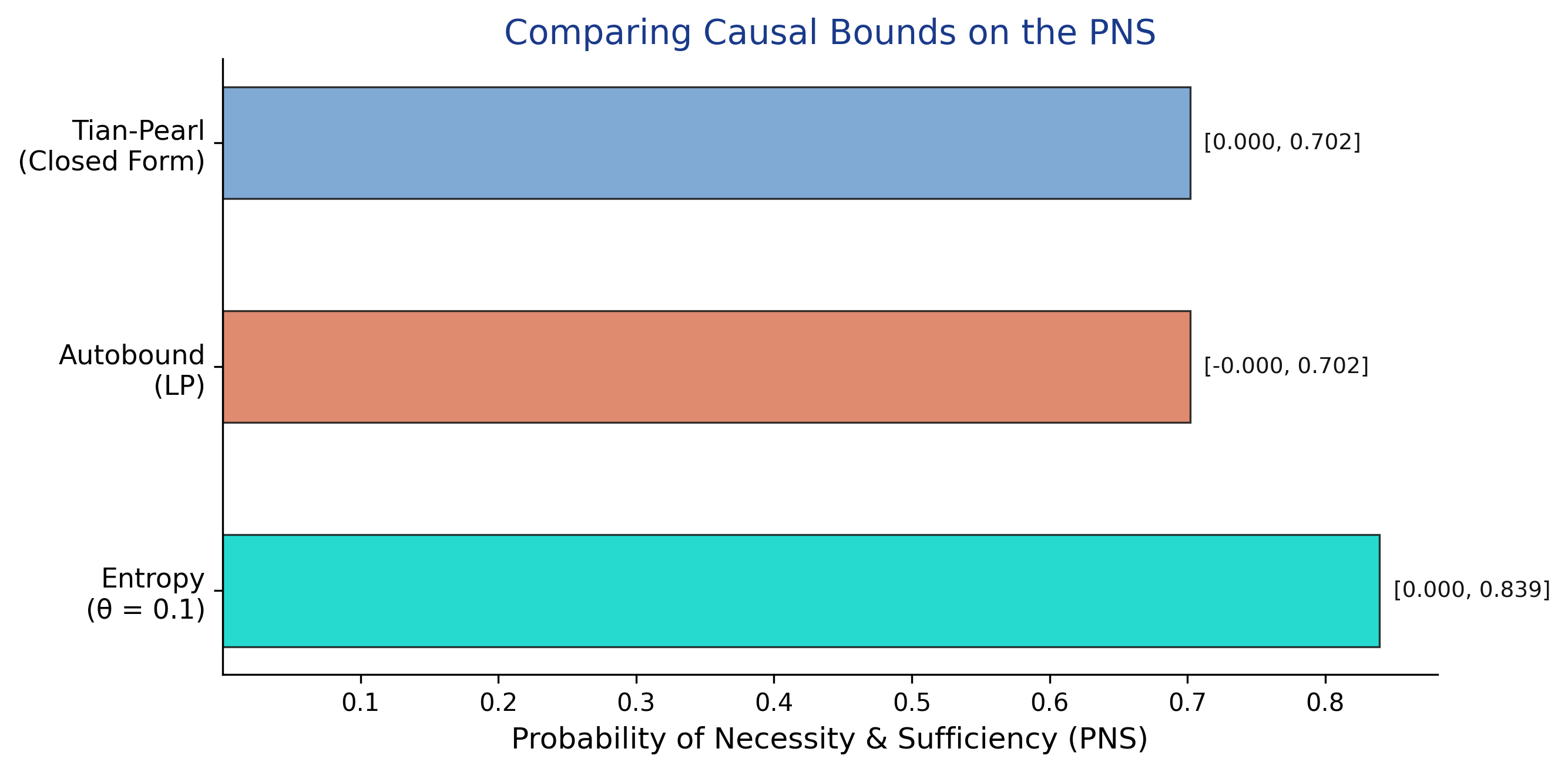
Tian–Pearl bounds answer a sharper question: was training necessary AND sufficient?
PNS is the share of workers who would get a job if trained and would not if untrained — individual-level causation, not a population average.
Tian–Pearl bounds: PNS \(\in [0.000,\ 0.702]\).
For PNS the closed form wins; entropy is weaker on counterfactual queries
Tian–Pearl and autobound coincide at \([0.000,\ 0.702]\); entropy (θ=0.1) is wider at \([0.000,\ 0.839]\).
The Resolution
Act III
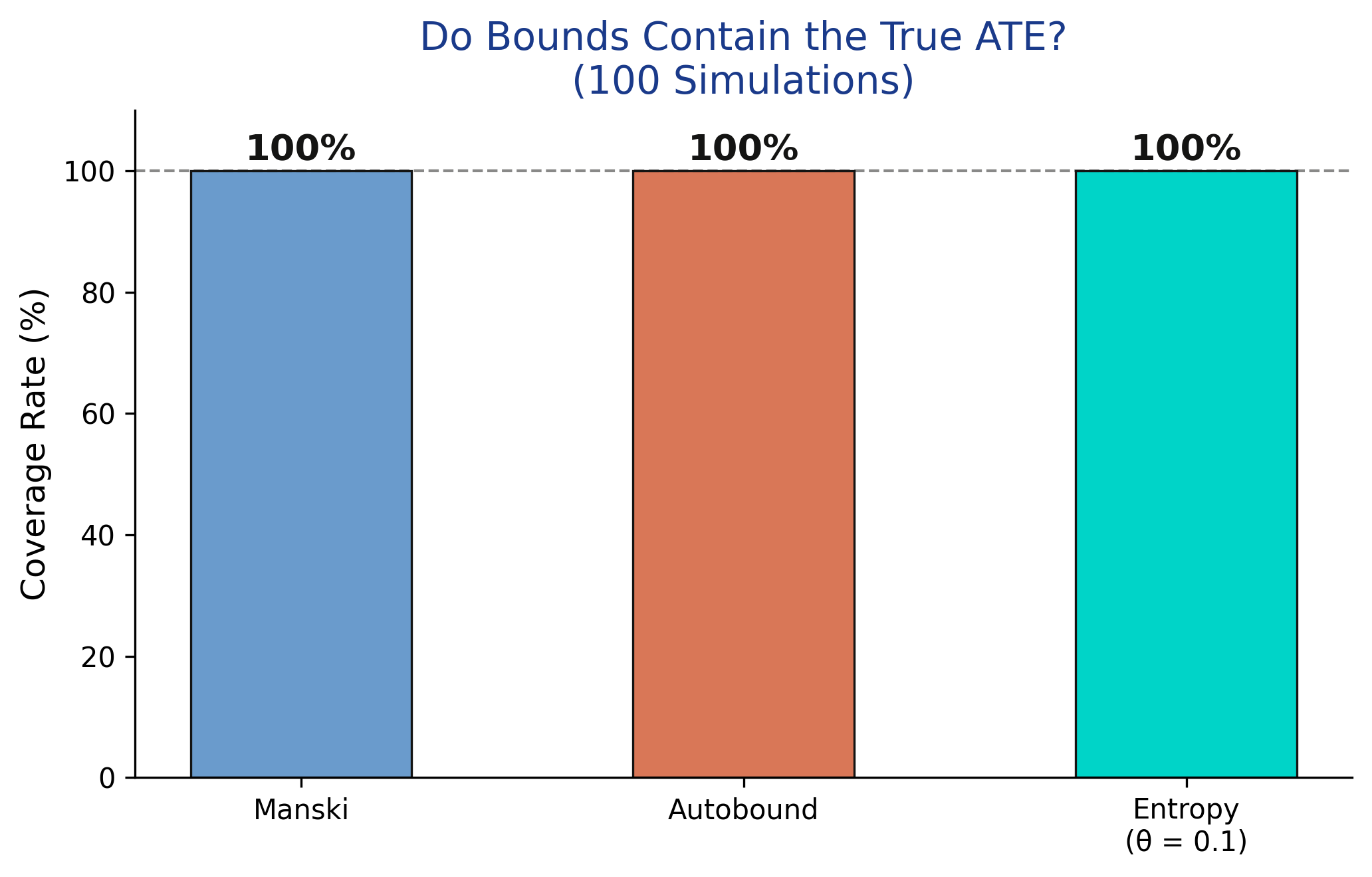
Every method covers the true ATE in 100 of 100 simulations
Coverage = 100% for Manski, autobound, and entropy across 100 resimulations — the bounds are valid, even when wide.
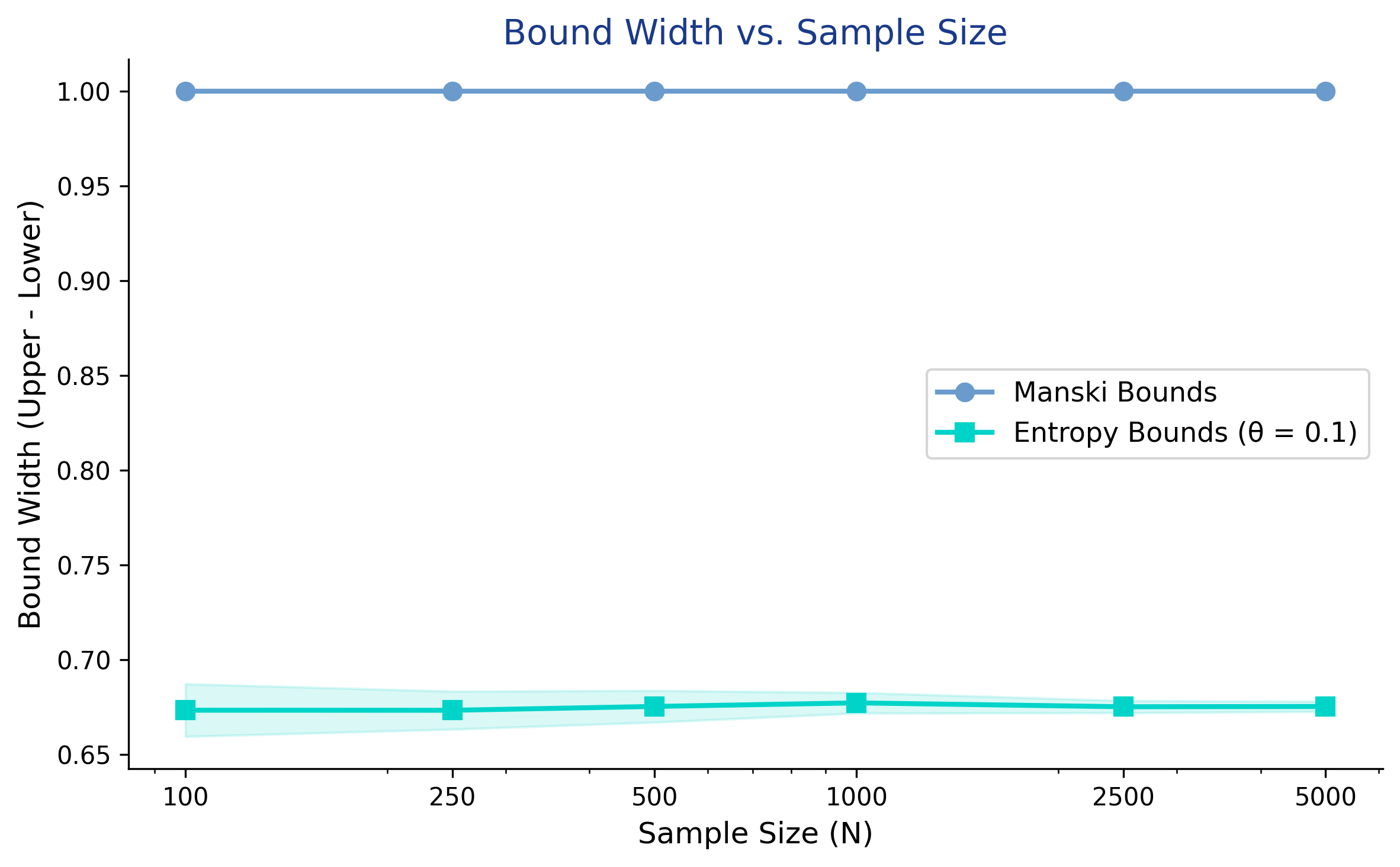
More data does NOT narrow these bounds — the width is identification, not noise
Manski width is pinned at 1.0 from N=100 to N=5,000; entropy hovers near 0.68 — only the scatter shrinks.
“Bounds that span zero are useless.” Are they?
Objection. If the interval includes zero, you cannot even sign the effect — so why bother?
Response. They still rule out the impossible: the ATE cannot exceed 0.702, so any “75-point benefit” claim is refuted. And the honesty is the point — the alternative is a precise number that is precisely wrong.
To tighten, add assumptions or data on the confounder — not more rows
What does NOT help
collecting more observations
a bigger N (width is fixed)
a fancier estimator on the same vars
What DOES help
an instrument \(Z\) (BinaryIV)
monotone treatment response \(Y(1)\ge Y(0)\)
measuring \(U\) directly; sensitivity analysis
The identified set narrows only when you bring new information to bear.
Without the confounder, the data give you a range — so report the range, honestly.