PCA for Development Indicators
Compressing correlated indicators into one composite index
97.97%variance captured by PC1
0.7071equal weight on each indicator
1.3e-15manual vs scikit-learn gap
Nagoya University (GSID)
June 11, 2026
The two indicators tell one story — in opposite directions
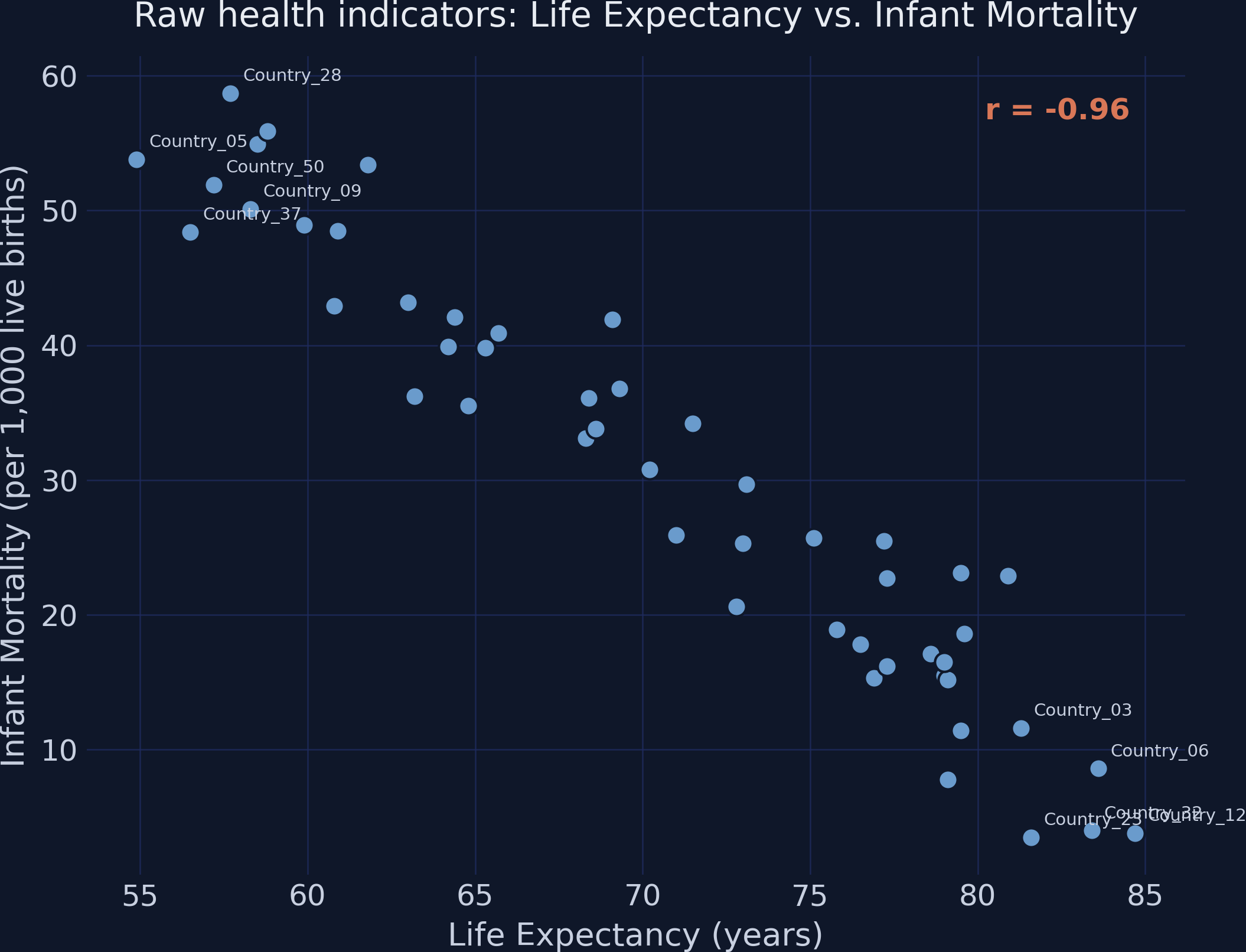
Raw health indicators for 50 simulated countries: a very strong negative relationship, \(r = -0.96\).
With \(r = 0.96\), PC1 absorbs almost all the variance: 97.97%
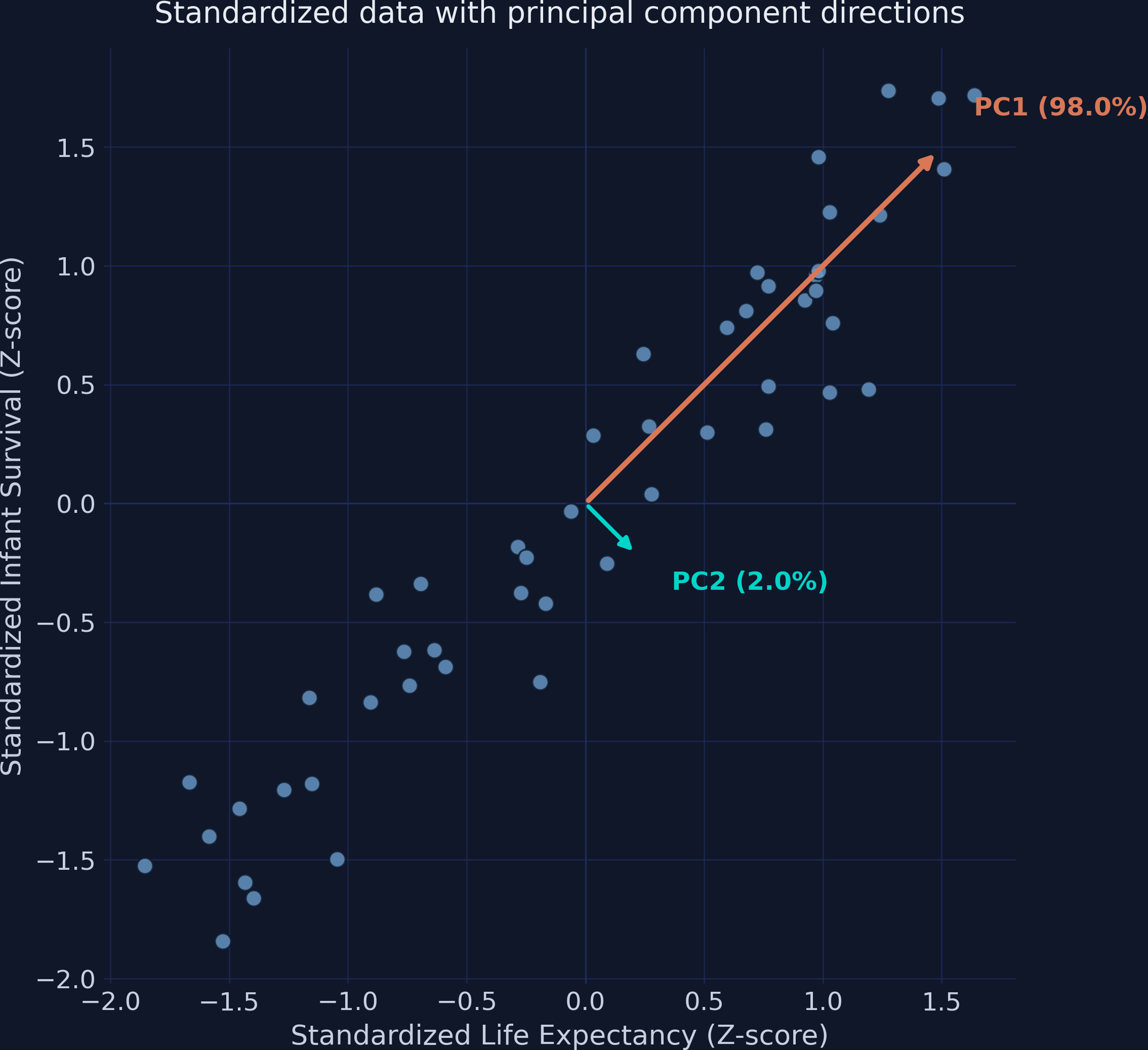
PC1 and PC2 eigenvector arrows over the standardized data — PC1 (orange) runs along the diagonal of maximum spread.
A single number keeps 98% of the information
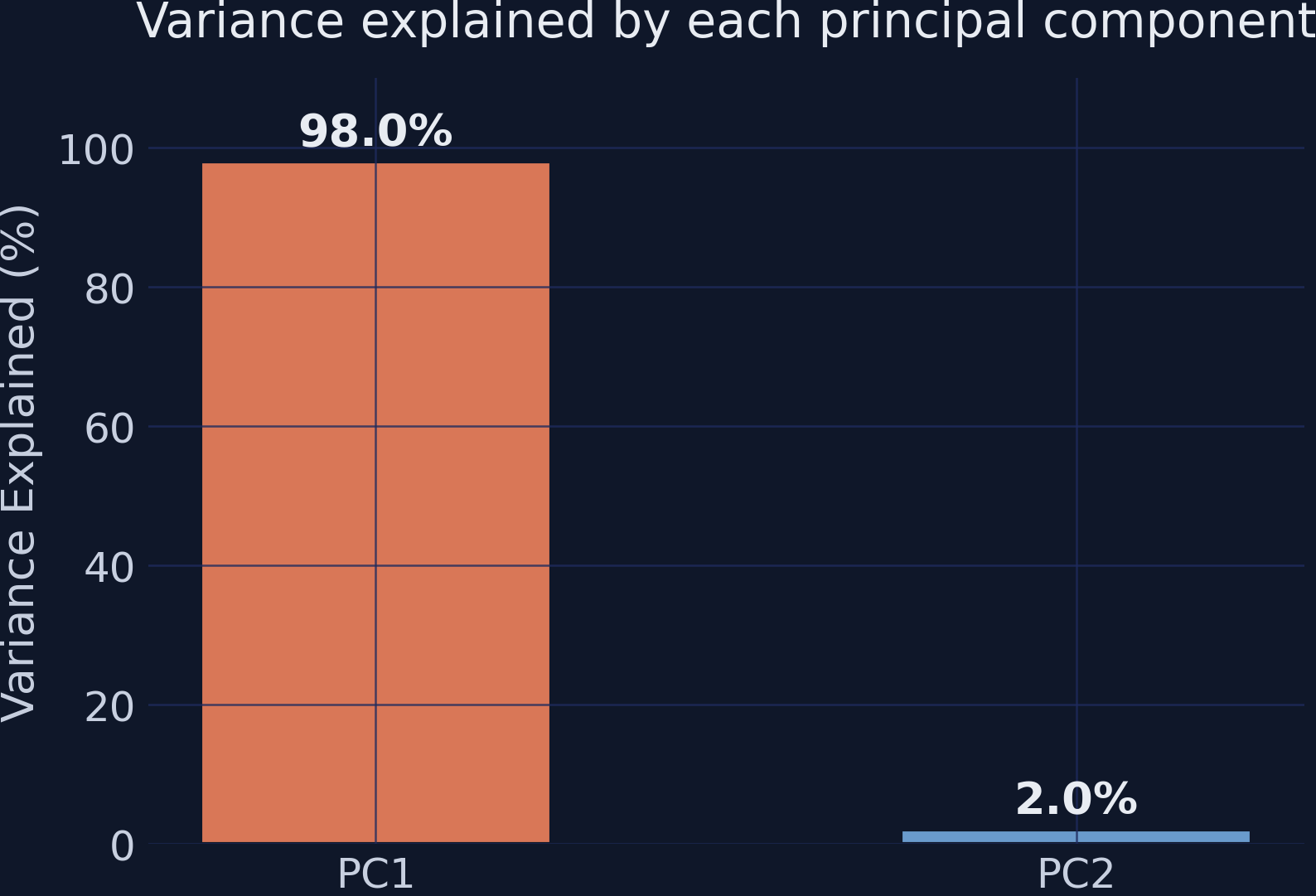
PC1 captures 98.0% of total variance; PC2 captures just 2.0%.
PC1 scores rank every country on one health axis
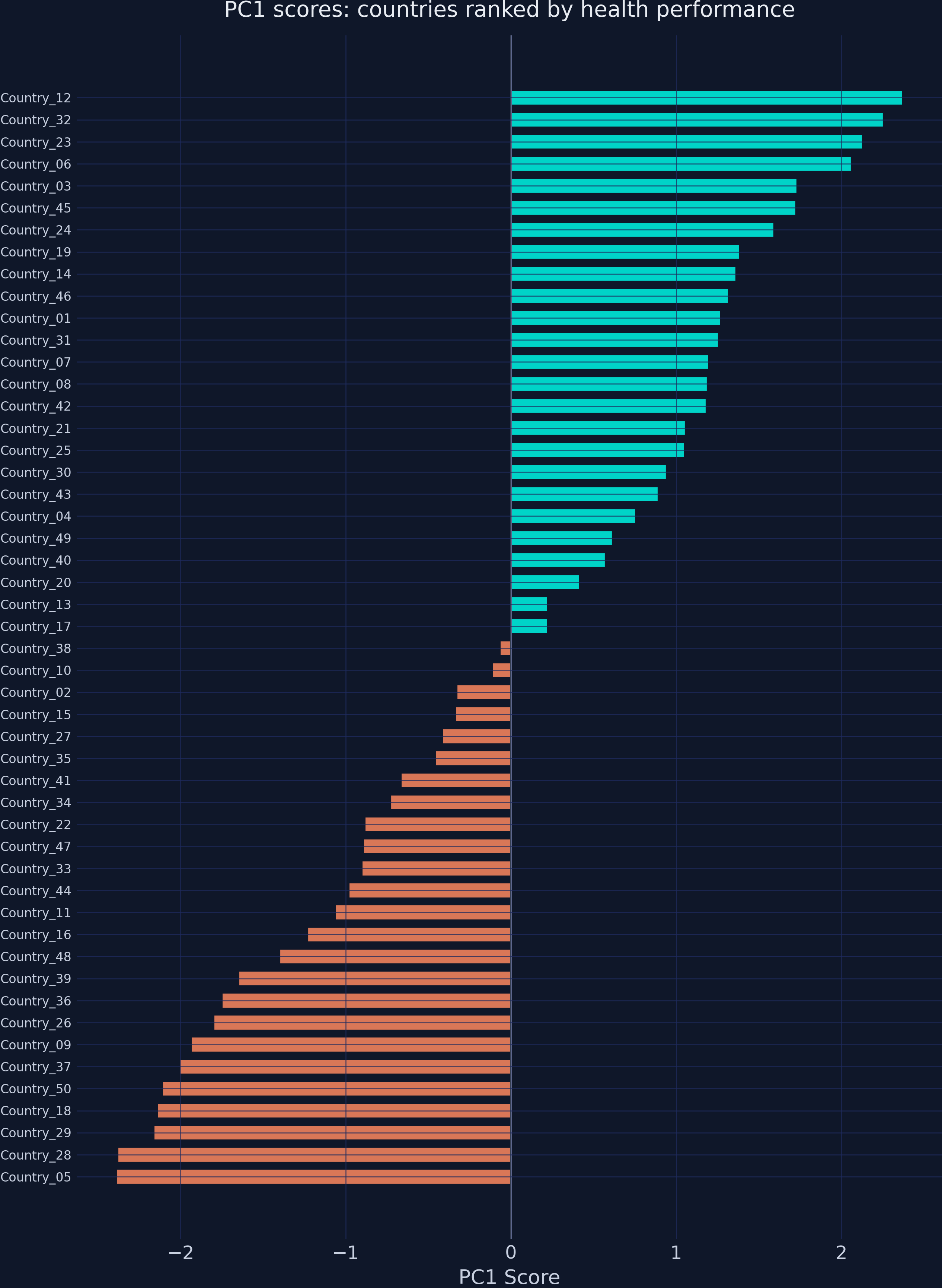
50 countries ranked by PC1 score — teal above average, orange below, roughly symmetric around zero.
The Health Index reveals a stark three-tier health divide
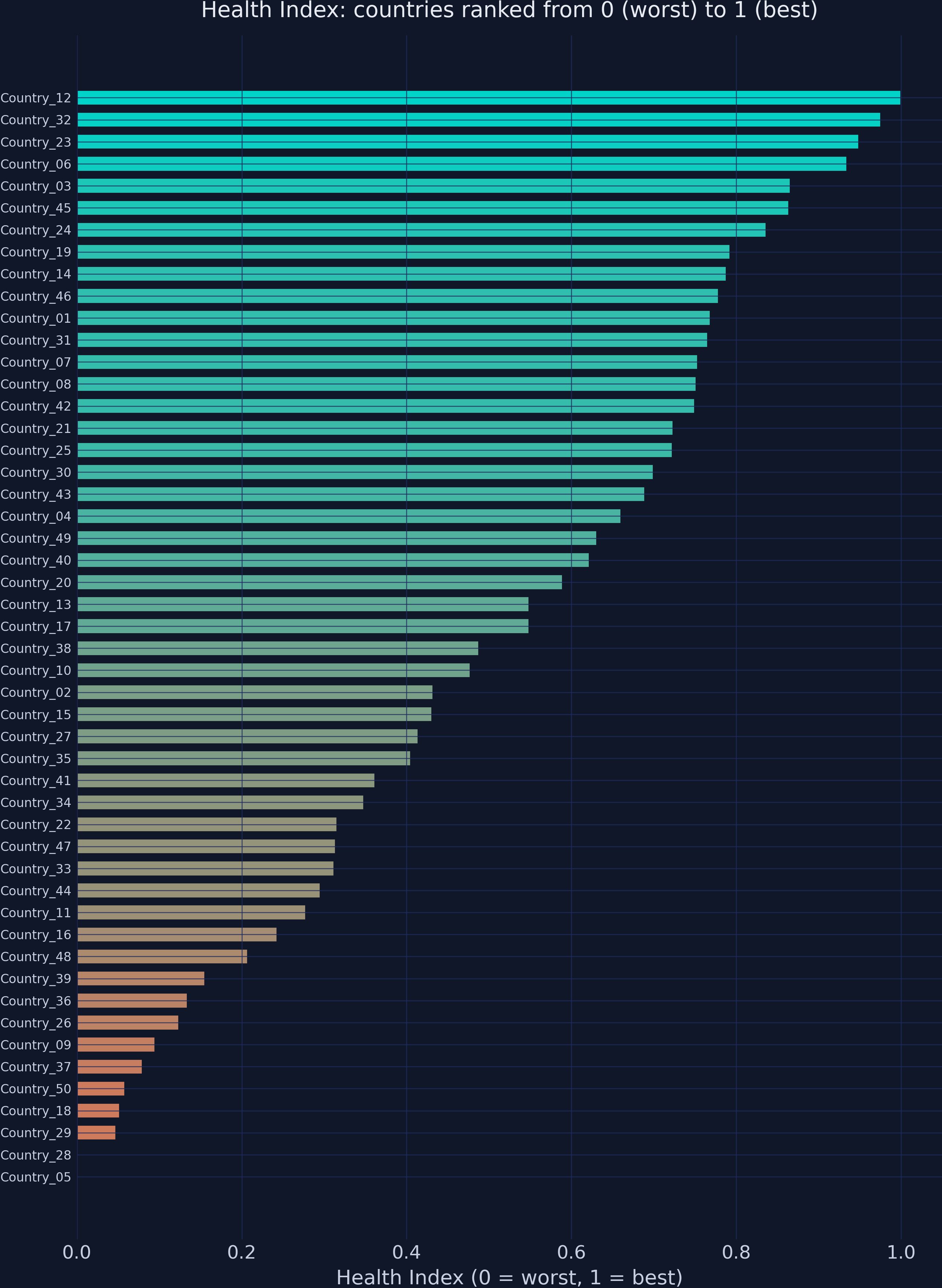
Health Index for 50 countries, orange (worst) to teal (best). Country_05 sits at exactly 0.00.
The manual pipeline matches scikit-learn to machine precision
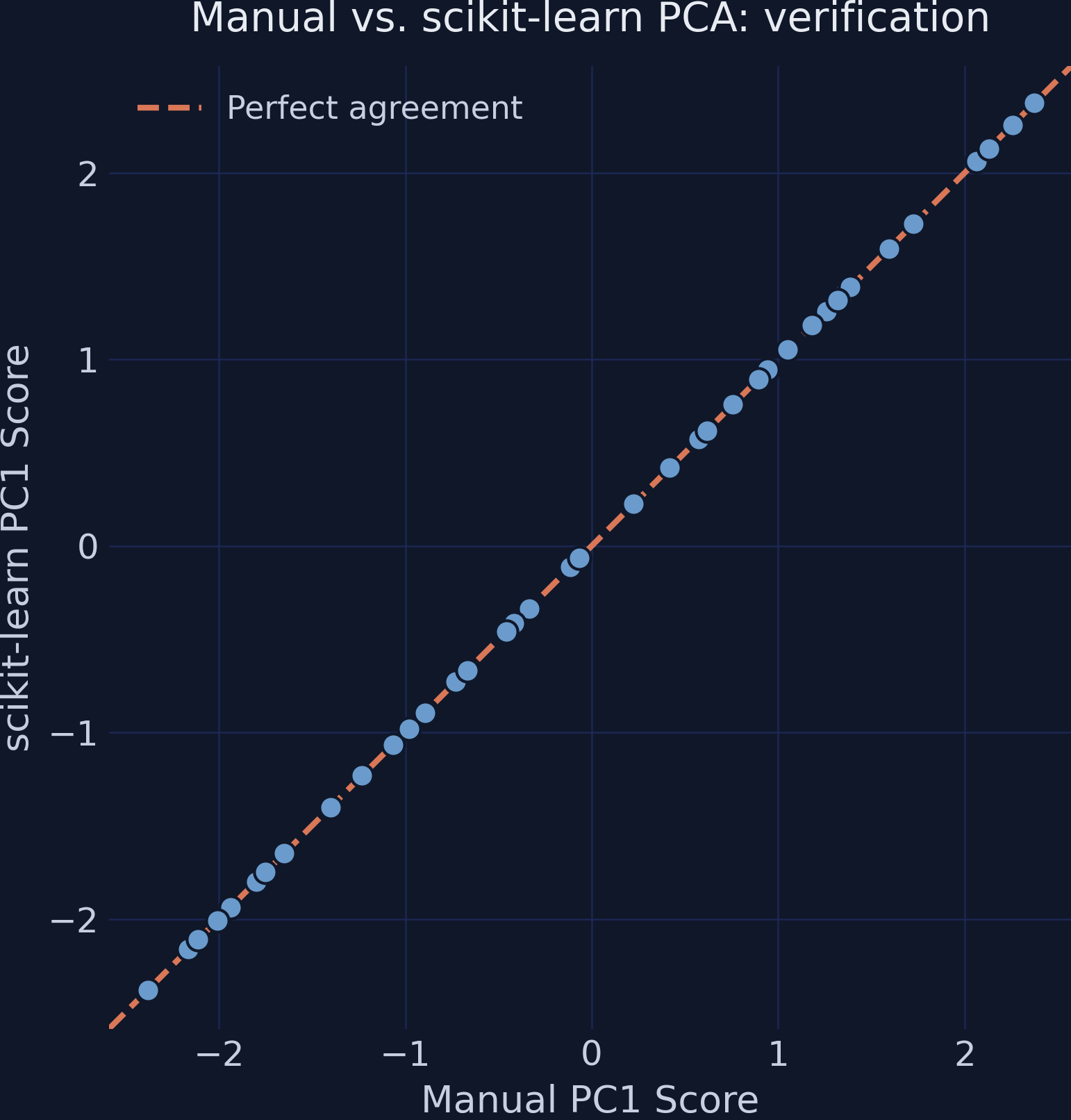
Manual vs scikit-learn PC1 scores: all 50 points fall on the 45-degree line of perfect agreement.