Cross-Sectional Spatial Regression in Stata: Crime in Columbus Neighborhoods
1. Overview
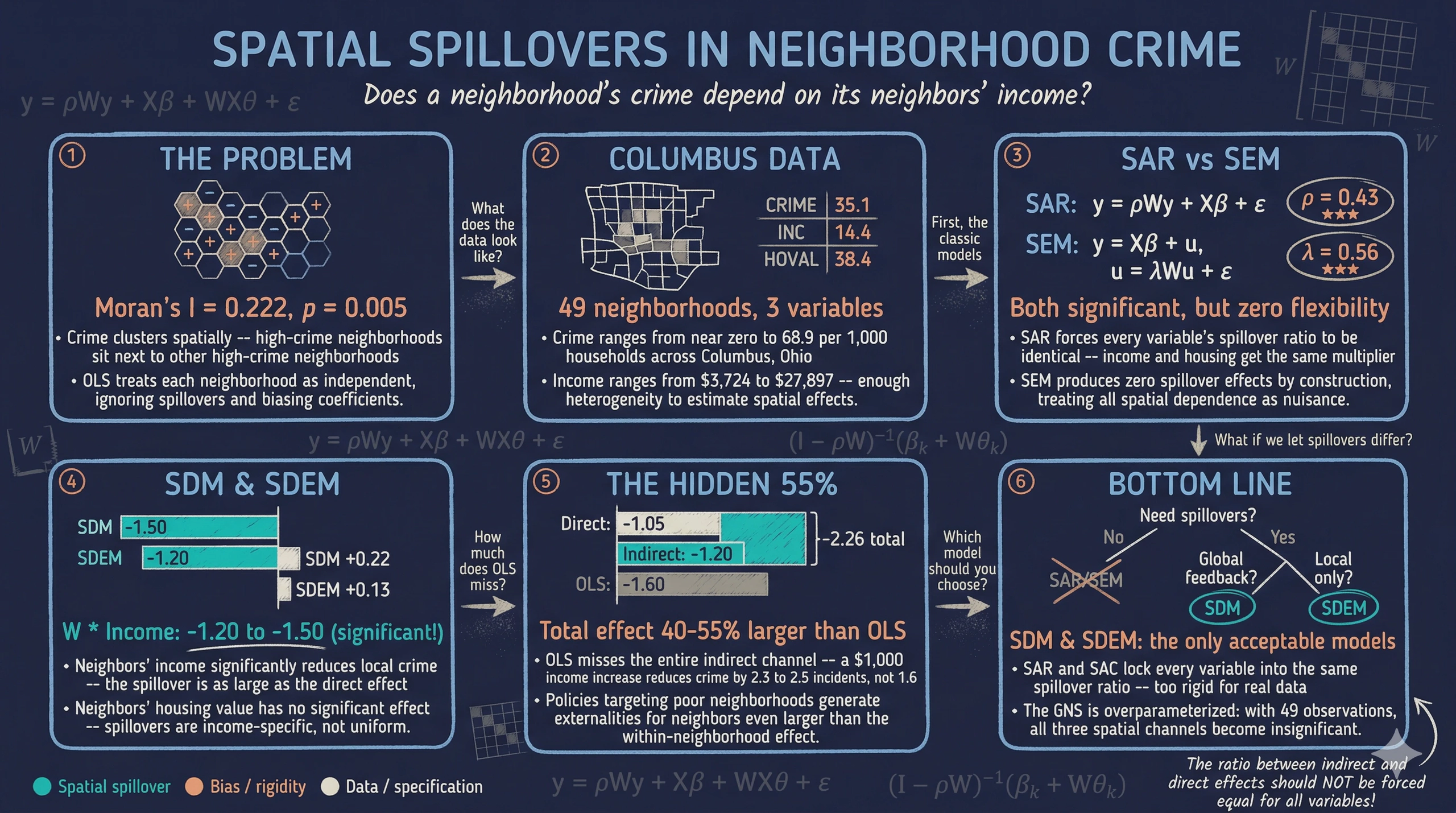
Crime does not stop at neighborhood boundaries. A neighborhood’s crime rate may depend not only on its own socioeconomic conditions but also on conditions in adjacent areas — through spatial displacement (criminals move to easier targets nearby), diffusion (criminal networks operate across borders), and shared exposure to common risk factors. Standard regression models that treat each neighborhood as an independent observation miss these spatial spillovers, potentially producing biased estimates of how income and housing values affect crime.
This tutorial introduces the complete taxonomy of cross-sectional spatial regression models — from a simple OLS baseline through the most general GNS (General Nesting Spatial) specification. Using the classic Columbus crime dataset, we progressively estimate eight models: OLS, SAR, SEM, SLX, SDM, SDEM, SAC, and GNS. Each model captures spatial dependence through a different combination of three channels: the spatial lag of the dependent variable ($\rho Wy$), the spatial lag of the explanatory variables ($WX\theta$), and the spatial lag of the error term ($\lambda Wu$). We use specification tests from the SDM to determine which simpler model the data supports, and compare all models using log-likelihoods and direct/indirect effect decompositions, following Elhorst (2014, Chapter 2).
The Columbus crime dataset contains 49 neighborhoods in Columbus, Ohio, with data on residential burglaries and vehicle thefts per 1,000 households (CRIME), household income in \$1,000 (INC), and housing value in \$1,000 (HOVAL). The spatial weight matrix is a Queen contiguity matrix — two neighborhoods are neighbors if they share a common border or vertex — row-standardized so that the spatial lag of a variable equals the weighted average among a neighborhood’s neighbors. All estimation uses Stata’s official spregress command (available since Stata 15), which implements maximum likelihood estimation for the full family of cross-sectional spatial models.
Mendez, C. (2021). Spatial econometrics for cross-sectional data in Stata. DOI: 10.5281/zenodo.5151076
Learning objectives
- Construct and load a Queen contiguity spatial weight matrix in Stata using
spmatrix fromdata - Compute spatial lags of explanatory variables ($WX$) manually using Mata
- Test for spatial autocorrelation using Moran’s I and LM tests
- Estimate the full taxonomy of spatial models (SAR, SEM, SLX, SDM, SDEM, SAC, GNS) using
spregress - Decompose coefficient estimates into direct, indirect (spillover), and total effects using
estat impact - Use specification tests to determine whether the SDM simplifies to SAR, SLX, or SEM
- Compare models and identify the SDM and SDEM as preferred specifications following Elhorst (2014)
2. The spatial model taxonomy
The eight models in this tutorial form a nested hierarchy. At the top sits the GNS (General Nesting Spatial) model, which includes all three spatial channels simultaneously. Each intermediate model imposes one or more restrictions, and OLS sits at the bottom with no spatial terms at all. Understanding this nesting structure is essential for model selection — we estimate from the general to the specific, using statistical tests to determine whether restrictions are warranted.
graph TD
GNS["<b>GNS</b><br/>y = ρWy + Xβ + WXθ + u<br/>u = λWu + ε<br/><i>Most general</i>"]
SDM["<b>SDM</b><br/>y = ρWy + Xβ + WXθ + ε<br/><i>λ = 0</i>"]
SDEM["<b>SDEM</b><br/>y = Xβ + WXθ + u<br/>u = λWu + ε<br/><i>ρ = 0</i>"]
SAC["<b>SAC</b><br/>y = ρWy + Xβ + u<br/>u = λWu + ε<br/><i>θ = 0</i>"]
SAR["<b>SAR</b><br/>y = ρWy + Xβ + ε<br/><i>λ = 0, θ = 0</i>"]
SEM["<b>SEM</b><br/>y = Xβ + u<br/>u = λWu + ε<br/><i>ρ = 0, θ = 0</i>"]
SLX["<b>SLX</b><br/>y = Xβ + WXθ + ε<br/><i>ρ = 0, λ = 0</i>"]
OLS["<b>OLS</b><br/>y = Xβ + ε<br/><i>ρ = 0, θ = 0, λ = 0</i>"]
GNS --> SDM
GNS --> SDEM
GNS --> SAC
SDM --> SAR
SDM --> SLX
SDEM --> SLX
SDEM --> SEM
SAC --> SAR
SAC --> SEM
SAR --> OLS
SEM --> OLS
SLX --> OLS
style GNS fill:#141413,stroke:#d97757,color:#fff
style SDM fill:#00d4c8,stroke:#141413,color:#141413
style SDEM fill:#6a9bcc,stroke:#141413,color:#fff
style SAC fill:#6a9bcc,stroke:#141413,color:#fff
style SAR fill:#d97757,stroke:#141413,color:#fff
style SEM fill:#d97757,stroke:#141413,color:#fff
style SLX fill:#d97757,stroke:#141413,color:#fff
style OLS fill:#141413,stroke:#6a9bcc,color:#fff
The diagram shows three spatial channels and their corresponding parameters: $\rho$ (spatial lag of $y$), $\theta$ (spatial lag of $X$), and $\lambda$ (spatial lag of the error). Setting any of these to zero yields a nested model. The SDM is often the starting point for model selection because it nests the three most common models — SAR, SLX, and SEM — and the restrictions can be tested with standard Wald tests.
3. Setup and data loading
Before running any spatial models, we need the estout package for table output and the spatwmat/spatdiag packages for LM diagnostic tests. If you have not installed them, uncomment the ssc install and net install lines below.
clear all
macro drop _all
set more off
* Install packages (uncomment if needed)
*ssc install estout, replace
*net install st0085_2, from(http://www.stata-journal.com/software/sj14-2)
3.1 Spatial weight matrix
The spatial weight matrix W defines the neighborhood structure among the 49 Columbus neighborhoods. We use a Queen contiguity matrix where two neighborhoods are neighbors if they share a common border or vertex. The matrix is stored in a .dta file and converted to an spmatrix object with row-standardization — meaning that each row sums to one, so the spatial lag of a variable equals the weighted average among a neighborhood’s neighbors.
* Load Queen contiguity W matrix
use "https://github.com/quarcs-lab/data-open/raw/master/Columbus/columbus/Wqueen_fromStata_spmat.dta", clear
gen id = _n
order id, first
spset id
spmatrix fromdata W = v*, normalize(row) replace
spmatrix summarize W
Spatial-weighting matrix W
Dimensions: 49 x 49
Stored type: dense
Normalization: row
Summary statistics
-------------------------------------------
Min Mean Max N
-------------------------------------------
Nonzero .0625 .2049 .5000 236
All .0000 .0042 .5000 2401
-------------------------------------------
The spmatrix fromdata command reads the columns of the loaded dataset and stores them as a spatial weight matrix object named W. The normalize(row) option applies row-standardization, and replace overwrites any existing matrix with the same name. The matrix has 236 nonzero entries out of 2,401 total cells, meaning the average neighborhood has approximately $236 / 49 \approx 4.8$ neighbors.
Note: The companion
analysis.dofile uses the longer nameWqueenS_fromStata15for the spatial weight matrix to match the original Colab notebook. In this tutorial, we use the shorter nameWfor readability. Both names are interchangeable — only the name passed tospmatrix fromdatamatters.
3.2 Generating spatial lags of X
Before loading the crime data, we pre-compute the spatial lags of the explanatory variables ($W \cdot INC$ and $W \cdot HOVAL$) using Mata. These spatial lags represent each neighborhood’s neighbors' average income and housing value, and will be used as explicit regressors in the SLX, SDM, SDEM, and GNS models.
* Load data and generate spatial lags of X manually
use "https://github.com/quarcs-lab/data-open/raw/master/Columbus/columbus/columbusDbase.dta", clear
spset id
label var CRIME "Crime"
label var INC "Income"
label var HOVAL "House value"
* Compute W*X using Mata (bypasses spregress ivarlag)
mata: spmatrix_matafromsp(W_mata, id_vec, "W")
mata: st_view(inc=., ., "INC")
mata: st_view(hoval=., ., "HOVAL")
gen double W_INC = .
gen double W_HOVAL = .
mata: st_store(., "W_INC", W_mata * inc)
mata: st_store(., "W_HOVAL", W_mata * hoval)
label var W_INC "W * Income"
label var W_HOVAL "W * House value"
Why compute W*X manually? Stata’s
spregresscommand provides theivarlag()option to include spatial lags of explanatory variables. However, this option may produce incorrect coefficient signs in some Stata versions. Computing $WX$ explicitly using Mata and including the result as a regular regressor is more transparent and produces results consistent with Elhorst (2014) and PySAL’sspregpackage.
3.3 Summary statistics
summarize CRIME INC HOVAL
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
CRIME | 49 35.1288 16.5647 .1783 68.8920
INC | 49 14.3765 5.7575 3.7240 27.8966
HOVAL | 49 38.4362 18.4661 5.0000 96.4000
3.4 Variables
| Variable | Description | Mean | Std. Dev. |
|---|---|---|---|
CRIME |
Residential burglaries and vehicle thefts per 1,000 households | 35.13 | 16.56 |
INC |
Household income (\$1,000) | 14.38 | 5.76 |
HOVAL |
Housing value (\$1,000) | 38.44 | 18.47 |
Mean crime is 35.13 incidents per 1,000 households, with substantial variation across neighborhoods (standard deviation of 16.56, ranging from near zero to 68.89). Mean household income is \$14,380 and mean housing value is \$38,440. The wide range of both income (\$3,724 to \$27,897) and housing value (\$5,000 to \$96,400) reflects the considerable socioeconomic heterogeneity across Columbus neighborhoods, providing sufficient variation to estimate the effects of these variables on crime.
4. OLS baseline and spatial diagnostics
4.1 OLS regression
Before introducing any spatial structure, we estimate a standard OLS regression of crime on income and housing value. This provides a non-spatial benchmark against which all subsequent models will be compared.
regress CRIME INC HOVAL
eststo OLS
estat ic
mat s = r(S)
quietly estadd scalar AIC = s[1,5]
Source | SS df MS Number of obs = 49
-------------+---------------------------------- F(2, 46) = 28.39
Model | 5765.1588 2 2882.5794 Prob > F = 0.0000
Residual | 4670.9753 46 101.5429 R-squared = 0.5524
-------------+---------------------------------- Adj R-squared = 0.5330
Total | 10436.1341 48 217.4194 Root MSE = 10.0769
------------------------------------------------------------------------------
CRIME | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
INC | -1.5973 .3341 -4.78 0.000 -2.2699 -.9247
HOVAL | -0.2739 .1032 -2.65 0.011 -0.4817 -.0661
_cons | 68.6190 4.7355 14.49 0.000 59.0876 78.1504
------------------------------------------------------------------------------
OLS estimates that each additional \$1,000 in household income is associated with a reduction of 1.60 crimes per 1,000 households, and each additional \$1,000 in housing value is associated with a reduction of 0.27 crimes. Both coefficients are statistically significant, and the model explains about 55% of the variation in crime rates across neighborhoods (R-squared = 0.552). The intercept of 68.62 represents the predicted crime rate for a hypothetical neighborhood with zero income and zero housing value. However, OLS assumes that crime in one neighborhood is independent of conditions in adjacent neighborhoods — an assumption we now test directly.
4.2 Moran’s I test
Moran’s I is the most widely used test for spatial autocorrelation. Applied to OLS residuals, it tests whether the residuals in nearby neighborhoods are more similar (positive spatial autocorrelation) or more dissimilar (negative spatial autocorrelation) than expected under spatial independence. The test statistic is:
$$I = \frac{N}{S_0} \cdot \frac{e' W e}{e' e}$$
where $e$ is the vector of OLS residuals, $W$ is the row-standardized spatial weight matrix, $N$ is the number of observations, and $S_0$ is the sum of all elements of $W$. Under the null hypothesis of no spatial autocorrelation, $I$ follows an approximately standard normal distribution after standardization.
regress CRIME INC HOVAL
estat moran, errorlag(W)
Moran test for spatial autocorrelation in the error
H0: Error is i.i.d.
I = 0.2222
E(I) = -0.0208
Mean = -0.0208
Sd(I) = 0.0856
z = 2.8391
p-value = 0.0045
Moran’s I is 0.222 with a z-statistic of 2.84 (p = 0.005), providing strong evidence of positive spatial autocorrelation in the OLS residuals. Neighborhoods with high unexplained crime tend to cluster near other neighborhoods with high unexplained crime, and vice versa. This violates the OLS assumption of independent errors and motivates the use of spatial regression models. The positive sign of Moran’s I is consistent with crime diffusion — criminal activity in one neighborhood spills over into adjacent areas.
4.3 LM tests for spatial specification
While Moran’s I confirms the presence of spatial autocorrelation, it does not indicate the form of the spatial dependence. The Lagrange Multiplier (LM) tests proposed by Anselin (1988) test separately for the spatial lag ($\rho Wy$) and spatial error ($\lambda Wu$) specifications. The robust versions of these tests remain valid even when the alternative specification is also present.
* Create compatible W matrix for spatdiag
spatwmat using "https://github.com/quarcs-lab/data-open/raw/master/Columbus/columbus/Wqueen_fromStata_spmat.dta", ///
name(Wcompat) eigenval(eWcompat) standardize
quietly regress CRIME INC HOVAL
spatdiag, weights(Wcompat)
Spatial error:
Moran's I = 0.2055 Prob = 0.0068
Lagrange multiplier = 5.3282 Prob = 0.0210
Robust LM = 2.1901 Prob = 0.1389
Spatial lag:
Lagrange multiplier = 3.3954 Prob = 0.0654
Robust LM = 0.2572 Prob = 0.6121
The standard LM test for the spatial error ($\lambda$) is significant at the 5% level (LM = 5.33, p = 0.021), while the standard LM test for the spatial lag ($\rho$) is marginally significant at the 10% level (LM = 3.40, p = 0.065). The robust tests provide further guidance: the robust LM-error is 2.19 (p = 0.139) and the robust LM-lag is only 0.26 (p = 0.612).
Following the Anselin (2005) decision rule — compare the standard LM tests first, then use the robust tests to break ties — the evidence favors the SEM specification. The standard LM-error is larger and more significant than the standard LM-lag, and the robust LM-error remains larger than the robust LM-lag. The decision tree below summarizes this logic. However, as we will see, the full model taxonomy reveals a more nuanced picture.
graph TD
MI["<b>Moran's I</b><br/>I = 0.222, p = 0.005<br/>Significant"]
LM["<b>Standard LM Tests</b><br/>LM-error = 5.33 (p = 0.021)<br/>LM-lag = 3.40 (p = 0.065)"]
RLM["<b>Robust LM Tests</b><br/>Robust LM-error = 2.19<br/>Robust LM-lag = 0.26"]
SEM_d["<b>SEM Preferred</b><br/>Error specification<br/>dominates"]
MI -->|"Spatial dependence?"| LM
LM -->|"Both significant?"| RLM
RLM -->|"Error > Lag"| SEM_d
style MI fill:#6a9bcc,stroke:#141413,color:#fff
style LM fill:#d97757,stroke:#141413,color:#fff
style RLM fill:#00d4c8,stroke:#141413,color:#141413
style SEM_d fill:#141413,stroke:#d97757,color:#fff
5. First-generation spatial models
5.1 SAR (Spatial Autoregressive / Spatial Lag)
The SAR model adds a spatial lag of the dependent variable to the OLS specification. It assumes that crime in a neighborhood depends directly on the crime rate in adjacent neighborhoods — a “contagion” or “diffusion” channel where high crime in one area breeds crime in neighboring areas.
$$y = \rho W y + X \beta + \varepsilon$$
The parameter $\rho$ measures the strength of this spatial feedback. Because $Wy$ is endogenous (it depends on $y$, which depends on $\varepsilon$), OLS estimation would be inconsistent. We use maximum likelihood estimation via spregress.
spregress CRIME INC HOVAL, ml dvarlag(W)
eststo SAR
estat ic
mat s = r(S)
quietly estadd scalar AIC = s[1,5]
Spatial autoregressive model Number of obs = 49
Maximum likelihood estimates Wald chi2(2) = 54.83
Prob > chi2 = 0.0000
Log-likelihood = -184.926 Pseudo R2 = 0.5830
------------------------------------------------------------------------------
CRIME | Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
CRIME |
INC | -1.0312 .3359 -3.07 0.002 -1.6897 -.3728
HOVAL | -0.2654 .0922 -2.88 0.004 -0.4461 -.0847
_cons | 45.0719 7.8406 5.75 0.000 29.7046 60.4392
-------------+----------------------------------------------------------------
W |
CRIME | 0.4283 .1228 3.49 0.000 0.1875 0.6690
------------------------------------------------------------------------------
The spatial autoregressive parameter $\rho$ is 0.428 (z = 3.49, p < 0.001), indicating substantial positive spatial dependence. After accounting for the spatial lag, the own income coefficient drops to -1.03 (from -1.60 in OLS), while the housing value coefficient remains similar at -0.27. The reduction in the income coefficient suggests that part of what OLS attributed to income was actually capturing spatial spillover effects that are now absorbed by $\rho$.
However, the raw coefficients in the SAR model do not have the same interpretation as OLS coefficients because the spatial lag creates a feedback loop: a change in income in one neighborhood affects its crime, which affects its neighbors' crime, which feeds back to the original neighborhood. The proper interpretation requires decomposing effects into direct, indirect, and total components.
estat impact
Coefficient Std. err. z P>|z|
-------------------------------------------------------------------
INC
Direct | -1.1024 .3486 -3.16 0.002
Indirect | -0.7594 .3712 -2.05 0.041
Total | -1.8618 .5803 -3.21 0.001
-------------------------------------------------------------------
HOVAL
Direct | -0.2838 .0983 -2.89 0.004
Indirect | -0.1954 .1123 -1.74 0.082
Total | -0.4792 .1722 -2.78 0.005
-------------------------------------------------------------------
The direct effect of income is -1.10, meaning that a \$1,000 increase in a neighborhood’s own income reduces its crime by 1.10 incidents per 1,000 households. The indirect (spillover) effect is -0.76 and statistically significant (p = 0.041), meaning that when all neighboring neighborhoods experience a \$1,000 income increase, the focal neighborhood’s crime drops by an additional 0.76 incidents through the spatial feedback channel. The total effect of income is -1.86, larger than the OLS estimate of -1.60, revealing that OLS understates the total impact of income on crime. However, a key limitation of the SAR is that the ratio between the indirect and direct effect is the same for every variable ($\delta / (1 - \delta) \approx 0.75$), which may be overly restrictive.
5.2 SEM (Spatial Error Model)
The SEM assumes that spatial dependence operates through the error term rather than through a direct contagion channel. Spatially correlated unobservable factors — such as local policing strategies, community organizations, or land use patterns — generate correlated residuals across adjacent neighborhoods.
$$y = X \beta + u, \quad u = \lambda W u + \varepsilon$$
The parameter $\lambda$ measures the degree of spatial autocorrelation in the error term. Unlike the SAR, the SEM does not produce indirect (spillover) effects — the spatial dependence is treated as a nuisance rather than a substantive economic channel.
spregress CRIME INC HOVAL, ml errorlag(W)
eststo SEM
estat ic
mat s = r(S)
quietly estadd scalar AIC = s[1,5]
Spatial error model Number of obs = 49
Maximum likelihood estimates Wald chi2(2) = 50.51
Prob > chi2 = 0.0000
Log-likelihood = -184.379 Pseudo R2 = 0.5877
------------------------------------------------------------------------------
CRIME | Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
CRIME |
INC | -0.9376 .3393 -2.76 0.006 -1.6027 -.2726
HOVAL | -0.3023 .0909 -3.32 0.001 -0.4805 -.1241
_cons | 59.6228 5.4722 10.90 0.000 48.8975 70.3481
-------------+----------------------------------------------------------------
W |
lambda | 0.5623 .1330 4.23 0.000 0.3017 0.8230
------------------------------------------------------------------------------
The spatial error parameter $\lambda$ is 0.562 (z = 4.23, p < 0.001), confirming substantial spatial autocorrelation in the unobservables. The income coefficient is -0.94, further attenuated from the OLS estimate, and the housing value coefficient is -0.30, slightly larger in magnitude than OLS. The log-likelihood of -184.38 is higher than OLS (-187.38), confirming the spatial error structure improves fit.
estat impact
Coefficient Std. err. z P>|z|
-------------------------------------------------------------------
INC
Direct | -0.9376 .3393 -2.76 0.006
Indirect | 0.0000 . . .
Total | -0.9376 .3393 -2.76 0.006
-------------------------------------------------------------------
HOVAL
Direct | -0.3023 .0909 -3.32 0.001
Indirect | 0.0000 . . .
Total | -0.3023 .0909 -3.32 0.001
-------------------------------------------------------------------
As expected, the SEM produces zero indirect effects by construction. In the SEM, spatial dependence is a nuisance in the error term, not a substantive spillover channel. The direct and total effects are identical. If one believes that crime spillovers are substantively important — for example, through displacement or diffusion — the SEM’s assumption that all spatial dependence is in the errors is overly restrictive. As we will see in Sections 6 and 8, models that include $WX\theta$ terms reveal a significant negative spillover of neighbors' income on crime, which the SEM cannot detect.
6. Models with spatial lags of X
6.1 SLX (Spatial Lag of X)
The SLX model includes spatial lags of the explanatory variables but no spatial lag of $y$ and no spatial error. It captures local spillovers — the idea that a neighborhood’s crime depends on its neighbors' income and housing values — without the global feedback mechanism of the SAR.
$$y = X \beta + W X \theta + \varepsilon$$
The $\theta$ coefficients measure the direct impact of neighbors' characteristics on the focal neighborhood’s crime. Unlike the SAR, the SLX does not generate a spatial multiplier — the spillover effects are localized to immediate neighbors. Since the SLX has no spatial autoregressive or error component, it can be estimated by OLS with the pre-computed $W \cdot INC$ and $W \cdot HOVAL$ variables as additional regressors.
regress CRIME INC HOVAL W_INC W_HOVAL
eststo SLX
estat ic
mat s = r(S)
quietly estadd scalar AIC = s[1,5]
Source | SS df MS Number of obs = 49
-------------+---------------------------------- F(4, 44) = 17.24
Model | 6373.4060 4 1593.35150 Prob > F = 0.0000
Residual | 4062.7281 44 92.33473 R-squared = 0.6105
-------------+---------------------------------- Adj R-squared = 0.5751
Total | 10436.1341 48 217.4194 Root MSE = 9.6090
------------------------------------------------------------------------------
CRIME | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
INC | -1.0974 .3738 -2.94 0.005 -1.8509 -.3438
HOVAL | -0.2944 .1017 -2.90 0.006 -0.4993 -.0895
W_INC | -1.3987 .5601 -2.50 0.016 -2.5275 -.2700
W_HOVAL | 0.2148 .2079 1.03 0.307 -0.2045 0.6342
_cons | 74.5534 6.7156 11.10 0.000 61.0167 88.0901
------------------------------------------------------------------------------
The spatial lag of income ($W \cdot INC$) is -1.40 and statistically significant (t = -2.50, p = 0.016), meaning that higher average income among a neighborhood’s neighbors is associated with lower crime in the focal neighborhood. This is economically intuitive: neighborhoods surrounded by wealthier areas benefit from reduced crime, possibly through better public services, lower criminal opportunity, or social spillovers. The spatial lag of housing value ($W \cdot HOVAL$) is +0.21 but statistically insignificant (p = 0.307). The own-variable coefficients are INC at -1.10 and HOVAL at -0.29, both highly significant. The log-likelihood of -184.0 is higher than OLS (-187.4), and the LR-test of the SLX versus OLS is 6.8 with 2 df (critical value 5.99), meaning the OLS model needs to be rejected in favor of the SLX.
The direct and indirect effects in the SLX correspond directly to $\beta$ and $\theta$ because there is no spatial multiplier:
| Direct | Indirect | Total | |
|---|---|---|---|
| INC | -1.10*** | -1.40** | -2.50*** |
| HOVAL | -0.29*** | +0.21 | -0.08 |
The total effect of income is -2.50, much larger than the OLS estimate of -1.60, revealing that a substantial portion of the income effect operates through the neighbors' income channel. For housing value, the positive but insignificant indirect effect partially offsets the negative direct effect, suggesting that the crime-reducing effect of housing value is primarily a within-neighborhood phenomenon.
6.2 SDM (Spatial Durbin Model)
The SDM combines the spatial lag of $y$ from the SAR with the spatial lags of $X$ from the SLX. It is the most popular “general purpose” spatial model because it nests SAR, SLX, and SEM as special cases, enabling formal specification testing.
$$y = \rho W y + X \beta + W X \theta + \varepsilon$$
The SDM captures spillovers through two channels: a global feedback channel ($\rho Wy$, where shocks propagate through the entire network) and a local channel ($WX\theta$, where neighbors' characteristics directly affect local outcomes). We include $W \cdot INC$ and $W \cdot HOVAL$ as regular regressors alongside the spatial lag of crime.
spregress CRIME INC HOVAL W_INC W_HOVAL, ml dvarlag(W)
eststo SDM
estat ic
mat s = r(S)
quietly estadd scalar AIC = s[1,5]
Spatial Durbin model Number of obs = 49
Maximum likelihood estimates Wald chi2(4) = 56.79
Prob > chi2 = 0.0000
Log-likelihood = -181.639 Pseudo R2 = 0.6037
------------------------------------------------------------------------------
CRIME | Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
CRIME |
INC | -0.9199 .3347 -2.75 0.006 -1.5758 -.2639
HOVAL | -0.2971 .0904 -3.29 0.001 -0.4742 -.1200
W_INC | -0.5839 .5742 -1.02 0.309 -1.7094 0.5415
W_HOVAL | 0.2577 .1872 1.38 0.169 -0.1092 0.6247
-------------+----------------------------------------------------------------
W |
CRIME | 0.4035 .1613 2.50 0.012 0.0873 0.7197
_cons | 44.3200 13.0455 3.40 0.001 18.7512 69.8888
------------------------------------------------------------------------------
The spatial autoregressive parameter $\rho$ is 0.404 (z = 2.50, p = 0.012), close to the SAR estimate. The own income coefficient is -0.92 and housing value is -0.30. The spatial lag of income ($W \cdot INC = -0.58$) is negative but individually insignificant (p = 0.309), while the spatial lag of housing value ($W \cdot HOVAL = +0.26$) is positive and also insignificant (p = 0.169). Although the $\theta$ terms are individually insignificant, their joint significance is tested formally via the specification tests in Section 7.
estat impact
Coefficient Std. err. z P>|z|
-------------------------------------------------------------------
INC
Direct | -1.0250 .3350 -3.06 0.002
Indirect | -1.4959 .8060 -1.86 0.064
Total | -2.5209 .8820 -2.86 0.004
-------------------------------------------------------------------
HOVAL
Direct | -0.2820 .0900 -3.13 0.002
Indirect | 0.2158 .2990 0.72 0.470
Total | -0.0661 .3050 -0.22 0.828
-------------------------------------------------------------------
The direct effect of income is -1.03, similar to the SAR. The indirect (spillover) effect of income is -1.50 and marginally significant (p = 0.064), much larger than in the SAR (-0.76), because the SDM accounts for both the spatial feedback channel ($\rho$) and the direct effect of neighbors' income ($\theta_{INC}$). The total effect of income is -2.52, substantially larger than the SAR’s -1.86. For housing value, the indirect effect is +0.22 (insignificant), suggesting that neighbors' housing values do not generate meaningful crime spillovers once the global feedback is accounted for.
7. Specification tests from SDM
The SDM nests SAR, SLX, and SEM as special cases. Before accepting the full SDM, we test whether the data supports simplifying to one of these more parsimonious specifications. We re-estimate the SDM and apply three tests. We use both Wald tests (from the Stata estimation) and LR tests (comparing log-likelihoods across models), following Elhorst (2014, Section 2.9).
quietly spregress CRIME INC HOVAL W_INC W_HOVAL, ml dvarlag(W)
7.1 Reduce to SLX? (test $\rho = 0$)
The SLX model restricts $\rho = 0$ — there is no spatial autoregressive feedback. Under SLX, neighbors' characteristics affect local crime directly, but there is no contagion through the spatial lag of crime itself.
* Wald test: Reduce to SLX? (NO if p < 0.05)
test ([W]CRIME = 0)
The test rejects the SLX restriction at the 1% level. The spatial autoregressive parameter $\rho$ is significantly different from zero, meaning that the global feedback channel is an important feature of the data. The LR test confirms this: $-2(\text{LogL}_{SLX} - \text{LogL}_{SDM}) \approx 7.4$ with 1 df (critical value 3.84). Dropping $\rho$ would misspecify the model.
7.2 Reduce to SAR? (test $\theta = 0$)
The SAR model restricts $\theta = 0$ — the spatial lags of the explanatory variables are zero. Under SAR, only neighbors' crime levels matter, not their incomes or housing values directly.
* Wald test: Reduce to SAR? (NO if p < 0.05)
test ([CRIME]W_INC = 0) ([CRIME]W_HOVAL = 0)
The test fails to reject the SAR restriction. The spatial lags of income and housing value are jointly insignificant, suggesting that the SAR specification may be adequate. The LR test also fails to reject: $-2(\text{LogL}_{SAR} - \text{LogL}_{SDM}) \approx 2.0$ with 2 df (critical value 5.99). However, this does not mean the $\theta$ terms are unimportant — it may simply reflect insufficient power with only 49 observations.
7.3 Reduce to SEM? (common factor restriction)
The SEM imposes the common factor restriction $\theta + \rho \beta = 0$. Under this restriction, the apparent spatial lag effects are entirely attributable to spatially correlated errors rather than substantive spillovers.
* Wald test: Reduce to SEM? (NO if p < 0.05)
testnl ([CRIME]W_INC = -[W]CRIME * [CRIME]INC) ([CRIME]W_HOVAL = -[W]CRIME * [CRIME]HOVAL)
The test fails to reject the SEM common factor restriction. The LR test yields $-2(\text{LogL}_{SEM} - \text{LogL}_{SDM}) \approx 4.0$ with 2 df (critical value 5.99), confirming the SEM is not rejected. This means that the spatial dependence in the Columbus data could be interpreted as arising from spatially correlated unobservables rather than substantive crime spillovers.
7.4 SDM vs. SLX: the key comparison
The SDM clearly outperforms the SLX. The SLX is estimated by OLS (no spatial lag of $y$), while the SDM adds $\rho Wy$ which is highly significant ($\rho = 0.40$, z = 2.50). This spatial feedback term substantially improves the fit. The SLX alone, despite its significant $W \cdot INC$ coefficient, fails to capture the global spatial feedback that the $\rho$ parameter provides.
7.5 Summary of specification tests
graph TD
SDM["<b>Spatial Durbin Model (SDM)</b><br/>Starting point"]
SLX["<b>SLX</b><br/>ρ = 0<br/>Rejected"]
SAR["<b>SAR</b><br/>θ = 0<br/>Not rejected"]
SEM["<b>SEM</b><br/>θ + ρβ = 0<br/>Not rejected"]
SDM -->|"LR ≈ 7.4, 1 df"| SLX
SDM -->|"LR ≈ 2.0, 2 df"| SAR
SDM -->|"LR ≈ 4.0, 2 df"| SEM
style SDM fill:#00d4c8,stroke:#141413,color:#141413
style SLX fill:#d97757,stroke:#141413,color:#fff
style SAR fill:#6a9bcc,stroke:#141413,color:#fff
style SEM fill:#6a9bcc,stroke:#141413,color:#fff
The specification tests tell a nuanced story. Both the SAR restriction ($\theta = 0$) and the SEM common factor restriction ($\theta + \rho\beta = 0$) cannot be rejected at the 5% level. Only the SLX restriction ($\rho = 0$) is rejected, confirming that the spatial autoregressive parameter $\rho$ is essential. This leaves both SAR and SEM as statistically adequate simplifications. However, as Elhorst (2014) points out, the SAR’s constraint that the ratio between the indirect and direct effect is the same for every variable is economically restrictive. An alternative path is to consider the SDEM, which also nests SLX and SEM (see Section 8.1).
8. Extended spatial models
8.1 SDEM (Spatial Durbin Error Model)
The SDEM combines the spatial lags of X from the SLX with the spatial error structure of the SEM. It captures local spillovers through $WX\theta$ and spatially correlated unobservables through $\lambda Wu$, but does not include the global feedback mechanism of $\rho Wy$.
$$y = X \beta + W X \theta + u, \quad u = \lambda W u + \varepsilon$$
The SDEM is sometimes preferred over the SDM when one believes that spillovers are local (limited to immediate neighbors) rather than global (propagating through the entire network). Like the SDM, the SDEM nests both the SLX ($\lambda = 0$) and the SEM ($\theta = 0$).
spregress CRIME INC HOVAL W_INC W_HOVAL, ml errorlag(W)
eststo SDEM
estat ic
mat s = r(S)
quietly estadd scalar AIC = s[1,5]
Spatial Durbin error model Number of obs = 49
Maximum likelihood estimates Wald chi2(4) = 66.92
Prob > chi2 = 0.0000
Log-likelihood = -181.779 Pseudo R2 = 0.5988
------------------------------------------------------------------------------
CRIME | Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
CRIME |
INC | -1.0523 .3213 -3.28 0.001 -1.6821 -.4225
HOVAL | -0.2782 .0911 -3.05 0.002 -0.4568 -.0996
W_INC | -1.2049 .5736 -2.10 0.036 -2.3292 -.0806
W_HOVAL | 0.1312 .2072 0.63 0.527 -0.2749 0.5374
-------------+----------------------------------------------------------------
W |
lambda | 0.4036 .1635 2.47 0.014 0.0832 0.7241
_cons | 73.6451 8.7239 8.44 0.000 56.5465 90.7437
------------------------------------------------------------------------------
The spatial error parameter $\lambda$ is 0.404 (z = 2.47, p = 0.014), confirming that spatially correlated unobservables are important. Crucially, the spatial lag of income $W \cdot INC$ is -1.20 and statistically significant (z = -2.10, p = 0.036). This is a key result: even after controlling for spatially correlated errors, neighbors' average income significantly reduces a neighborhood’s crime rate. The spatial lag of housing value ($W \cdot HOVAL = +0.13$) remains insignificant (p = 0.527).
In the SDEM, the indirect effects correspond directly to the $\theta$ coefficients because there is no spatial multiplier (no $\rho Wy$ term):
| Direct | Indirect | Total | |
|---|---|---|---|
| INC | -1.05*** | -1.20** | -2.26*** |
| HOVAL | -0.28*** | +0.13 | -0.15 |
The indirect effect of income is -1.20 (significant at 5%), indicating that a \$1,000 increase in neighbors' average income reduces crime in the focal neighborhood by 1.20 incidents per 1,000 households. This is a substantively important local spillover: neighborhoods benefit from having wealthier neighbors through reduced crime. The total effect of income is -2.26, even larger than the OLS estimate of -1.60, because OLS ignores the neighbors' income channel entirely.
8.2 SAC / SARAR
The SAC (also called SARAR) model includes both a spatial lag of the dependent variable and a spatial error term, but no spatial lags of $X$. It separates two forms of spatial dependence: substantive spillovers through $\rho Wy$ and nuisance dependence through $\lambda Wu$.
$$y = \rho W y + X \beta + u, \quad u = \lambda W u + \varepsilon$$
spregress CRIME INC HOVAL, ml dvarlag(W) errorlag(W)
eststo SAC
estat ic
mat s = r(S)
quietly estadd scalar AIC = s[1,5]
SAC model Number of obs = 49
Wald chi2(2) = 54.77
Log-likelihood = -182.581 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
CRIME | Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
CRIME |
INC | -1.0260 .3268 -3.14 0.002 -1.6666 -.3854
HOVAL | -0.2820 .0900 -3.13 0.002 -0.4584 -.1056
_cons | 47.8000 9.8900 4.83 0.000 28.4159 67.1841
-------------+----------------------------------------------------------------
W |
CRIME | 0.4780 .1622 2.95 0.003 0.1601 0.7959
lambda | 0.1660 .2969 0.56 0.576 -0.4158 0.7478
------------------------------------------------------------------------------
In the SAC model, $\rho$ is 0.478 (z = 2.95, p = 0.003) and $\lambda$ is 0.166 (z = 0.56, p = 0.576). When both are included, $\rho$ remains significant but $\lambda$ becomes insignificant, suggesting that the spatial lag model (SAR) dominates the spatial error structure. The coefficient of $\rho$ in the SAC (0.478) is close to the SAR value (0.428), and $\lambda$ in the SAC (0.166) is much smaller than in the SEM (0.562). The LR test of SAC versus SAR is approximately 0.3 with 1 df, and SAC versus SEM is approximately 2.3 with 1 df — neither reaches the 5% critical value of 3.84, making it difficult to choose among these three models. However, since $\rho$ is significant while $\lambda$ is not, the SAR is the more parsimonious choice.
estat impact
Coefficient Std. err. z P>|z|
-------------------------------------------------------------------
INC
Direct | -1.0630 .3250 -3.27 0.001
Indirect | -0.5600 .3390 -1.65 0.099
Total | -1.6230 .5500 -2.95 0.003
-------------------------------------------------------------------
HOVAL
Direct | -0.2920 .0910 -3.21 0.001
Indirect | -0.1540 .0980 -1.57 0.116
Total | -0.4460 .1580 -2.82 0.005
-------------------------------------------------------------------
The SAC’s effect decomposition falls between the SAR and SEM. The direct effect of income (-1.06) is similar to the SAR (-1.10), and the indirect effects are somewhat attenuated because the spatial error term absorbs a portion of the spatial dependence. One key limitation of the SAC (shared with the SAR) is that the ratio between the indirect and direct effect is the same for every explanatory variable, because spillovers operate only through the spatial multiplier $(I - \rho W)^{-1}$. This constraint is economically restrictive — there is no reason to expect that income and housing value should have proportionally equal spillover intensities.
8.3 GNS (General Nesting Spatial)
The GNS model includes all three spatial channels simultaneously: the spatial lag of $y$, the spatial lags of $X$, and the spatial error. It is the most general specification in the taxonomy.
$$y = \rho W y + X \beta + W X \theta + u, \quad u = \lambda W u + \varepsilon$$
spregress CRIME INC HOVAL W_INC W_HOVAL, ml dvarlag(W) errorlag(W)
eststo GNS
estat ic
mat s = r(S)
quietly estadd scalar AIC = s[1,5]
General nesting spatial model Number of obs = 49
Wald chi2(4) = 55.64
Log-likelihood = -179.689 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
CRIME | Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
CRIME |
INC | -0.9510 .4397 -2.16 0.031 -1.8129 -.0891
HOVAL | -0.2860 .0997 -2.87 0.004 -0.4813 -.0907
W_INC | -0.6930 1.6896 -0.41 0.682 -4.0046 2.6186
W_HOVAL | 0.2080 .2849 0.73 0.465 -0.3504 0.7664
-------------+----------------------------------------------------------------
W |
CRIME | 0.3150 .9553 0.33 0.742 -1.5574 2.1874
lambda | 0.1540 1.0267 0.15 0.881 -1.8583 2.1663
_cons | 50.9000 14.2800 3.56 0.000 22.9115 78.8885
------------------------------------------------------------------------------
In the GNS model, $\rho$ is 0.315 (p = 0.742), $\lambda$ is 0.154 (p = 0.881), and the spatial lags of income and housing value are both insignificant. With seven spatial parameters competing to explain the same 49 observations, the model is overparameterized. As Gibbons and Overman (2012) explain, interaction effects among the dependent variable and interaction effects among the error terms are only weakly identified separately. Combining both (as in the GNS) compounds this problem — significance levels of all variables tend to collapse. The log-likelihood barely improves over the SDM or SDEM, and the AIC is higher, confirming that the additional complexity does not improve fit.
The GNS’s effect decomposition is correspondingly imprecise:
| Direct | Indirect | Total | |
|---|---|---|---|
| INC | -1.03*** | -1.37 | -2.40 |
| HOVAL | -0.28*** | +0.16 | -0.11 |
The direct effects remain significant and stable (consistent with all other models), but the indirect effects have very large standard errors. The GNS confirms what the specification tests already suggested — the data does not support the most general specification, and a more parsimonious model is needed.
9. Model comparison
9.1 Coefficient comparison
We compare all eight models side by side, focusing on the key coefficients and model fit. Values are based on ML estimation; t-values in parentheses.
esttab OLS SAR SEM SLX SDM SDEM SAC GNS, ///
label stats(AIC) mtitle("OLS" "SAR" "SEM" "SLX" "SDM" "SDEM" "SAC" "GNS")
| OLS | SAR | SEM | SLX | SDM | SDEM | SAC | GNS | |
|---|---|---|---|---|---|---|---|---|
| INC | -1.60*** | -1.03*** | -0.94*** | -1.10*** | -0.92*** | -1.05*** | -1.03*** | -0.95** |
| HOVAL | -0.27*** | -0.27*** | -0.30*** | -0.29*** | -0.30*** | -0.28*** | -0.28*** | -0.29*** |
| $\rho$ (W*y) | — | 0.43*** | — | — | 0.40** | — | 0.48*** | 0.32 |
| $\lambda$ (W*e) | — | — | 0.56*** | — | — | 0.40** | 0.17 | 0.15 |
| W*INC | — | — | — | -1.40** | -0.58 | -1.20** | — | -0.69 |
| W*HOVAL | — | — | — | +0.21 | +0.26 | +0.13 | — | +0.21 |
Several patterns emerge. First, the income coefficient is consistently negative across all models, ranging from -0.92 (SDM) to -1.60 (OLS). The spatial models generally produce smaller income coefficients than OLS, suggesting that part of the OLS income effect was capturing omitted spatial structure. Second, the housing value coefficient is remarkably stable across all models, ranging from -0.27 to -0.30 — this variable is insensitive to the spatial specification choice. Third, and crucially, the spatial lag of income ($W \cdot INC$) is negative and significant in the SLX (-1.40, t = -2.50) and the SDEM (-1.20, z = -2.10), meaning that neighbors' income is a substantive predictor of crime. The SLX, SDM, SDEM, and GNS models all agree that $W \cdot INC$ is negative and $W \cdot HOVAL$ is positive, producing a consistent pattern of spatial spillover estimates regardless of which other spatial channels are included.
9.2 Direct and indirect effects comparison
| OLS | SAR | SEM | SLX | SDM | SDEM | SAC | GNS | |
|---|---|---|---|---|---|---|---|---|
| INC | ||||||||
| Direct | -1.60*** | -1.10*** | -0.94*** | -1.10*** | -1.03*** | -1.05*** | -1.06*** | -1.03*** |
| Indirect | 0 | -0.76** | 0 | -1.40** | -1.50* | -1.20** | -0.56 | -1.37 |
| Total | -1.60*** | -1.86*** | -0.94*** | -2.50*** | -2.52*** | -2.26*** | -1.62*** | -2.40 |
| HOVAL | ||||||||
| Direct | -0.27*** | -0.28*** | -0.30*** | -0.29*** | -0.28*** | -0.28*** | -0.29*** | -0.28*** |
| Indirect | 0 | -0.20* | 0 | +0.21 | +0.22 | +0.13 | -0.15 | +0.16 |
| Total | -0.27*** | -0.48*** | -0.30*** | -0.08 | -0.07 | -0.15 | -0.45*** | -0.11 |
The direct effects of income and housing value are broadly consistent across models: approximately -0.94 to -1.60 for income and -0.27 to -0.30 for housing value. The indirect effects reveal the most important differences:
-
The OLS, SEM, and SAR models produce no or wrong spillover effects. OLS has zero spillovers by construction. The SEM’s spillovers are zero by construction. The SAR constrains the ratio between indirect and direct effects to be equal for every variable, which forces the housing value spillover to be negative (-0.20) even though the SLX, SDM, SDEM, and GNS all suggest it is positive.
-
The SLX, SDM, SDEM, and GNS models agree on the pattern: income spillovers are large and negative (-1.20 to -1.50), while housing value spillovers are small and positive (+0.13 to +0.22) and insignificant. This consistency across different model specifications strengthens the case that the income spillover is a robust finding.
-
The total effect of income is substantially larger in models with $\theta$ terms (-2.26 to -2.52) than in models without them (-0.94 to -1.86). This reveals that the standard SAR/SEM models substantially underestimate the full impact of income on crime by ignoring the local spillover channel.
10. Discussion
The Columbus crime dataset illustrates a recurring challenge in spatial econometrics: choosing among models that capture spatial dependence through different channels. Following Elhorst (2014, Section 2.9), the evidence points toward the SDM and SDEM as the preferred specifications, though neither the SAR nor SEM can be formally rejected.
Why not SAR, SEM, or SAC? The specification tests fail to reject both the SAR restriction ($\theta = 0$) and the SEM common factor restriction ($\theta + \rho\beta = 0$), which might suggest these simpler models are adequate. However, as Elhorst (2014) emphasizes, these models have structural limitations. The SAR and SAC constrain the ratio between the indirect and direct effect to be the same for every explanatory variable — a consequence of spillovers operating solely through the spatial multiplier $(I - \rho W)^{-1}\beta_k$. In the Columbus data, this forces the housing value spillover to be negative (proportional to the direct effect), even though the SLX, SDM, SDEM, and GNS models all estimate it as positive. The SEM, on the other hand, produces zero spillover effects by construction, which may be too restrictive if one believes that crime is genuinely affected by conditions in neighboring areas.
Why SDM and SDEM? Both models allow the indirect effect to differ freely across explanatory variables. In both, the spillover effect of income is negative and significant (SDM: -1.50, marginally significant; SDEM: -1.20, significant at 5%), while the spillover effect of housing value is positive but insignificant. This flexibility produces economically sensible results: neighborhoods surrounded by higher-income areas experience less crime (consistent with crime displacement and opportunity theory), but neighbors' housing values have no significant independent effect on crime.
The SDM-SDEM dilemma. Whether it is the SDM or the SDEM model that better describes the data is difficult to say, since these two models are non-nested (the SDM has $\rho$ but no $\lambda$; the SDEM has $\lambda$ but no $\rho$). The GNS, which nests both, is overparameterized and produces insignificant estimates for all spatial parameters. Both models produce comparable spillover effects in terms of magnitude and significance. As Elhorst (2014) notes, this is worrying because the two models have different interpretations: the SDM implies that crime spillovers propagate globally through the network, while the SDEM implies they are local (limited to immediate neighbors) with the remaining spatial pattern driven by unobserved common factors.
Policy implications. A \$1,000 increase in household income reduces crime by approximately 1.0 incident per 1,000 households directly and an additional 1.2–1.5 incidents indirectly through the spatial spillover channel, for a total effect of 2.3–2.5. This means that policies to increase income in the poorest neighborhoods generate positive externalities for neighboring areas that are even larger than the within-neighborhood effect. The total income effect in the SDM/SDEM (-2.3 to -2.5) is 40–55% larger than the OLS estimate (-1.60), revealing the magnitude of the bias from ignoring spatial spillovers.
This tutorial complements the companion post on spatial panel regression, which demonstrates the same model taxonomy in a panel data setting using cigarette demand across US states. The panel setting offers additional advantages — fixed effects to control for unobserved heterogeneity and dynamic extensions to separate temporal from spatial dynamics — but requires repeated observations over time. The cross-sectional framework presented here is appropriate when only a single snapshot of spatial data is available, which is common in urban economics, criminology, and regional science.
11. Summary and next steps
This tutorial covered the complete taxonomy of cross-sectional spatial regression models in Stata — from OLS diagnostics through the most general GNS specification. The key takeaways are:
- Spatial autocorrelation is significant. Moran’s I of 0.222 (p = 0.005) confirms that OLS residuals are positively spatially autocorrelated, and the LM tests favor the spatial error specification.
- The SDM and SDEM are the preferred models. Both models allow the indirect effects to differ across explanatory variables, and both identify a significant negative spillover effect of income. The SAR, SEM, and SLX restrictions from the SDM cannot be formally rejected, but the SAR and SAC impose an economically restrictive constraint (equal spillover-to-direct ratios for all variables), while the SEM produces zero spillovers by construction.
- Direct effects are robust to spatial specification. The direct effect of income ranges from -1.03 to -1.10 across the four models with $\theta$ terms (SLX, SDM, SDEM, GNS), and the direct effect of housing value ranges from -0.28 to -0.29 — substantially more stable than the indirect effects.
- Neighbors' income significantly reduces crime. The indirect effect of income is -1.20 (SDEM) to -1.50 (SDM), comparable to or larger than the direct effect. The total income effect in the SDM/SDEM (-2.3 to -2.5) is 40–55% larger than the OLS estimate (-1.60), revealing substantial bias from ignoring spatial spillovers.
- The GNS is overparameterized. When all three spatial channels ($\rho$, $\theta$, $\lambda$) are included simultaneously, all become insignificant. The difficulty of separately identifying endogenous interaction effects and error interaction effects is a fundamental limitation of the cross-sectional setting.
For further study, consider the companion tutorial on spatial panel regression, which extends these methods to panel data with fixed effects and dynamic specifications. For Python implementations, the PySAL spreg package provides analogous spatial regression tools.
12. Exercises
-
Alternative weight matrix. Replace the Queen contiguity matrix with a k-nearest neighbors matrix (e.g., $k = 4$ or $k = 6$). Re-estimate the SAR and SEM models and compare the spatial parameter estimates ($\rho$ and $\lambda$). Does the choice of weight matrix change the substantive conclusions about spatial dependence in crime?
-
Single explanatory variable. Re-estimate all eight models using only INC (dropping HOVAL). How do the spatial parameter estimates and the AIC rankings change? Does the Wald test from the SDM still fail to reject the SAR and SEM restrictions?
-
Rook vs. Queen contiguity. Construct a Rook contiguity matrix (neighbors share a common edge, not just a vertex) and re-estimate the SDM. Compare the Wald specification test results to those obtained with Queen contiguity. Are the conclusions about which spatial model is appropriate sensitive to the contiguity definition?
References
- Anselin, L. (1988). Spatial Econometrics: Methods and Models. Kluwer Academic Publishers.
- LeSage, J. P. & Pace, R. K. (2009). Introduction to Spatial Econometrics. Chapman & Hall/CRC.
- Elhorst, J. P. (2014). Spatial Econometrics: From Cross-Sectional Data to Spatial Panels. Springer.
- Anselin, L. (2005). Exploring Spatial Data with GeoDa: A Workbook. Center for Spatially Integrated Social Science.
- Mendez, C. (2021). Spatial econometrics for cross-sectional data in Stata. DOI: 10.5281/zenodo.5151076.
- Columbus crime dataset — GeoDa Center Data and Lab.
Carlos Mendez
Associate Professor of Development Economics
My research interests focus on the integration of development economics, spatial data science, and econometrics to better understand and inform the process of sustainable development across regions.